Observability
Gather insights and collect data about your AI model’s performance.
Scalability
MindsDB is built with cloud-native principles in mind, making it well-suited for deployment in cloud environments where scalability is key.
Security
MindsDB connects directly with your data source, which limits risks of data leaks during the ETL process.
Customization
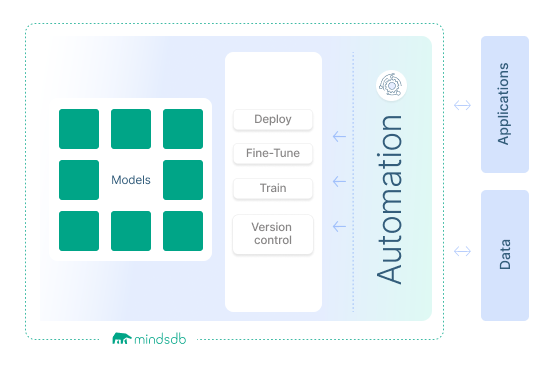
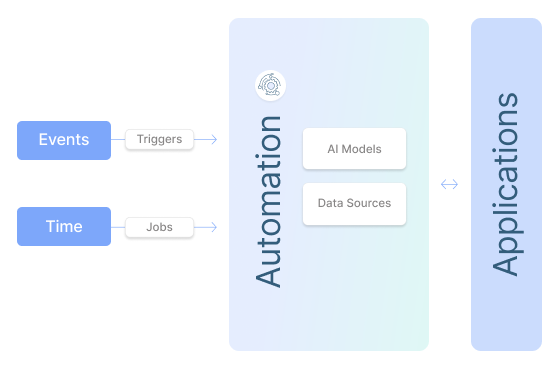
With nearly 200 integrations, any developer can create AI customized for their purpose, faster and more securely.