OpenAI Just Published the Best Case for Why You Need Minds Enterprise

Jorge Torres, Co-founder & CEO at MindsDB

When the company building AGI can't answer simple questions about itself, maybe the BIG problem is no longer intelligence, but the 15 tools between you and the answers?
OpenAI recently published a detailed account of Kepler, their internal AI data agent. It's a fascinating piece; the kind of "here's how the sausage we made that you can’t buy was made". I'd encourage everyone to read it. The article is, at its core, a confession.
Think about this: The company building the most advanced AI on the planet, the one with GPT-5.whatever humming away in its data centers, couldn't answer the question "How many ChatGPT Pro users are in France?" without sending analysts on an archaeological expedition across 70,000 datasets, 15 different tools, and troves of data. A question that should take seconds to minutes required, in their words, extended Slack conversations and sometimes meetings just to figure out how to access the data.
Let that marinate. Not "How do we achieve artificial general intelligence." Not "How do we align superintelligent systems with human values," but “How many paying customers do we have in a given location?”
Terrifying, right? Because if OpenAI (with functionally unlimited cash, engineering talent, and the most powerful language models ever created) needed to build a bespoke, non-commercializable internal tool to answer basic business questions from their own data...you must be wondering: what chance does your company have, with a stressful Jira board and a data team that's already three sprints behind?
The Diagnosis Is Universal. The Prescription Is Not.
To their credit, OpenAI didn't just build their internal tool and call it a day. They articulated why this problem is so hard, and their diagnosis reads like a clinical description of every enterprise data environment I've ever encountered.
The data is everywhere and nowhere. It lives in warehouses, lakes, SaaS platforms, spreadsheets that someone named "FINAL_v3_actually_final.xlsx," and the institutional memory of that one analyst who's been there since the seed round. Getting a coherent answer means stitching together fragments from systems that were never designed to talk to each other. It's not a data problem. It's a Babel problem.
Correct SQL is a miracle, not a given. OpenAI's team pointed out that even after you find the right tables, generating accurate queries is treacherous. Many-to-many joins. Filter pushdown errors. Unhandled nulls. Any one of these can silently produce results that are wrong by an order of magnitude. Their exact words: "Missing one nuance can be catastrophic when making important business decisions." This is a company that employs some of the best engineers alive, saying, "SQL is hard, and our people get it wrong." If your response to that is "well, our analysts don't make those mistakes," I'd gently suggest you might just not be catching them.
Context lives in the hallways, not the schemas. Two tables can look identical in structure and mean completely different things. One tracks all user traffic. The other tracks only first-party ChatGPT traffic. The difference between them? It's buried in a Slack thread from 2023, a Notion page three people have bookmarked, and the verbal institutional knowledge of someone who may or may not still work there. No amount of column metadata is going to surface that distinction. You need a system that understands the meaning of data, not just its shape.
OpenAI's answer was an internal tool: a dedicated internal agent powered by GPT-5.2, combining RAG over metadata, live warehouse queries, integration with Slack and Google Docs and Notion for institutional context, a memory system for continuous improvement, and codex tests for validation. And, unfortunately for you, it took a team of world-class engineers that most can’t afford or convince to join you unless you are the hottest of the AI companies, and an extended build-and-iterate cycle. Anyway, it covers the full analytics workflow: discovery, SQL generation, report publishing. It's available to OpenAI employees through Slack, a web interface, and their IDEs.
It is, by any measure, a serious piece of engineering.
It is also explicitly not for sale. OpenAI has stated they have no plans to commercialize it.
So: their article? A definitive diagnosis of why enterprise data is broken, paired with a solution that exactly zero other companies on Earth can use. Helpful. right?
The Part Where I Point Out That You, Too, Can Solve This
Well, luckily for all of you, there is Minds Enterprise by MindsDB.
Now, I know and I realize this is where yours truly, the CEO of MindsDB, tells you that our soup cures your illness, and you're calibrating your skepticism accordingly. Fair! But stay with me, because the architecture of the solution and the principles OpenAI validated with their not-for-sale internal tool are the same principles that drove our solution (Minds), and therefore are available to anyone who isn't OpenAI. So yes, I invite you to go ahead and try Minds.
I am not saying this just because we have been plumbers of data for AI since forever, and we have built the most widely-deployed AI Query engine in the world (https://github.com/mindsdb/mindsdb), but because we have been working on these problems for such a long time, that my emotional therapist knows them by heart, and because we have known they are very painful, we have built a solution that has matured for multiple years now. Let me walk you through it:
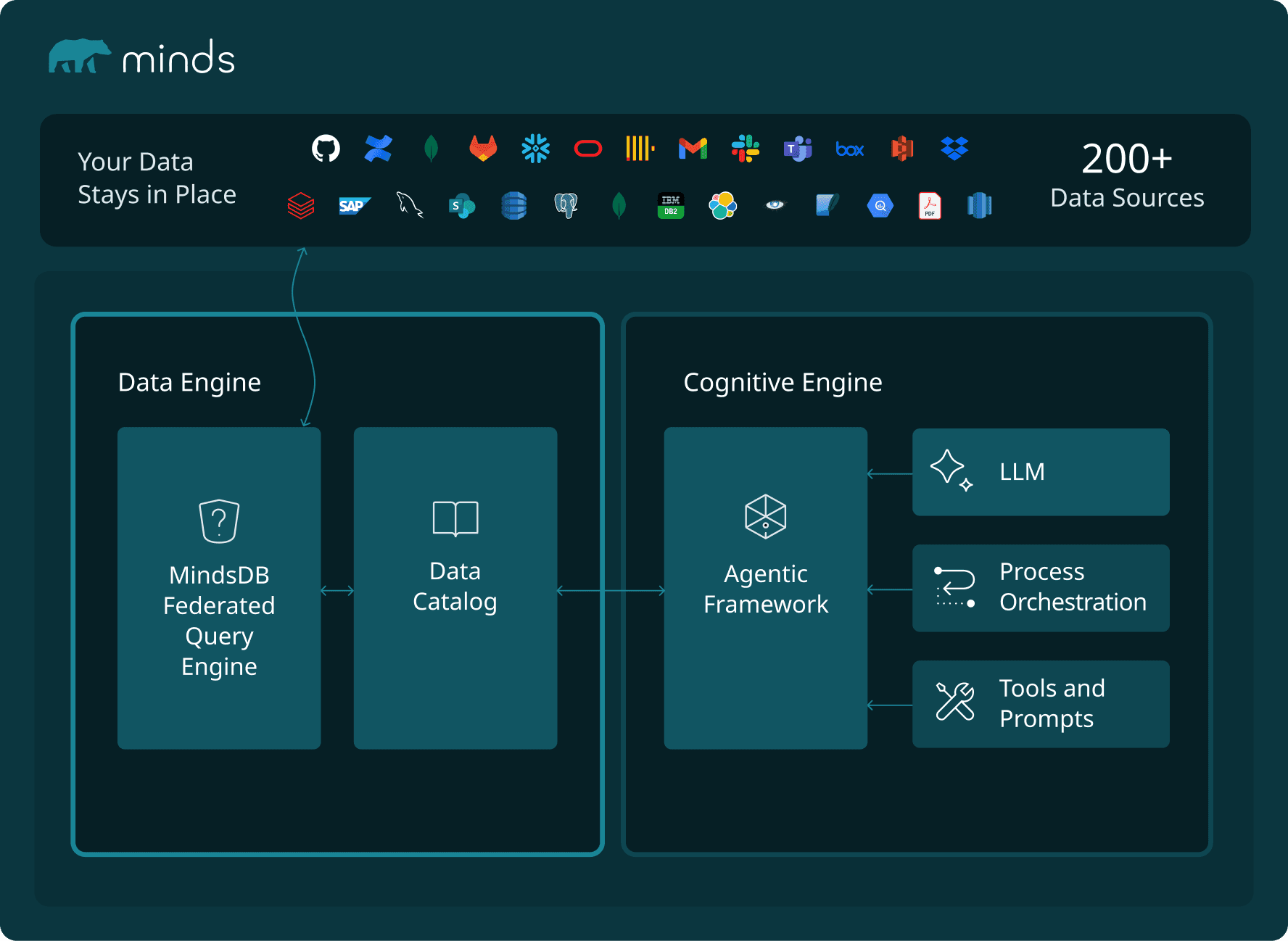
The Babel problem. OpenAI had to build custom integrations for their internal data systems. Every company that tries to replicate Kepler will face the same integration tax, and most will abandon the project when they realize the plumbing alone takes longer than the AI part. Minds connects to over 200 data sources natively: Databases, SaaS applications, file systems… Structured, unstructured, the kind of data that defies categorization. No data movement. No ETL pipelines. Your data stays where it is, and Minds federates across all of it. That's not a feature list — it's the difference between a project that ships and one that dies in integration hell.
The SQL accuracy problem. Kepler uses RAG over metadata to understand what tables mean, then generates SQL that accounts for the treacherous edge cases OpenAI described. Minds does the same thing, but combines parametric search (text-to-SQL) with semantic search (RAG), retaining the precision of SQL. The distinction matters: Minds doesn't just translate your question into SQL and hope for the best. It reasons about how to get the right answer, which is possible if you can do structured and unstructured queries in the same language, and the reason why we extended the SQL language to do that.
The context problem. OpenAI invested heavily in grounding Kepler with institutional knowledge — metric definitions, product context, the kind of nuance that separates a correct answer from a technically-valid-but-wrong one. Their team noted that context gets you 80–90% of the way there, but the final corrections require memory. Minds ships with Knowledge Bases that index massive volumes of structured and unstructured data, and you can embed your business rules, metric definitions, and domain context directly. It's not a chatbot stapled to a database. It's a system that learns what your data means.
The trust problem. This is the one that matters most, and it's the one most AI analytics tools get catastrophically wrong. If you can't see how an AI arrived at an answer, you can't verify it, defend it in a board meeting, or explain it to a regulator. Kepler's article gestures at this but doesn't elaborate. Minds makes it explicit: every answer comes with a visible chain of thought: what data was selected. From which source. How it informed the response. The reasoning is logged and observable. Not because transparency is a nice feature, but because in enterprise analytics, an answer you can't audit is worse than no answer at all.
When 'We'll Get Back to You Next Week' Becomes a Competitive Disadvantage
Here's the part that is very exciting: OpenAI's data team reported that their analysts were spending enormous amounts of time on what should be routine questions. Their internal agent (Kepler) brought that down dramatically. At MindsDB, we see the same pattern with our customers: what used to take an analyst five days—building a dashboard, extracting insights from raw data across multiple sources—takes minutes with Minds.
Five days to five minutes. That's not an incremental improvement. That's the difference between "we'll get back to you next week" and "here's the answer, and here's exactly how I got it." That's the difference between data-informed decisions and decisions that happen to have data attached retroactively.
Gartner predicts 40% of enterprise applications will embed AI agents by the end of 2026. Databricks reports 327% growth in multi-agent workflows. These aren't predictions anymore — they're deadlines. And if the most sophisticated AI company in the world needed a purpose-built data agent to make sense of its own information, that's not a niche use case. That's a universal requirement.
Conclusion
You don't need to be OpenAI to have OpenAI's data problems. You just need data, questions, and not enough hours in the day. Which, last time I checked, describes every company on Earth.
OpenAI built their internal agent (Kepler) because they had to. Because even with the best models, the best engineers, and functionally unlimited compute and money, data fragmentation, SQL complexity, and missing context made their own data almost unusable for basic business questions. They spent years solving it.
The architecture they described: federated queries, metadata grounding, institutional context, transparent reasoning, conversational exploration, continuous learning(!) isn't novel to us. It's a validation of what we've been building in the open, as a product, for years.
The difference? Well, you cannot buy their internal agent; it is tailor-made for OpenAI and not for sale, but you can use Minds. It deploys anywhere: any cloud, on-premises, or serverlessly in MindsDB's cloud. It serves not just data scientists, but anyone in finance, marketing, operations, or customer success who has a question and doesn't want to wait five days for the answer. Like our CRO often explains: Minds’ job is simple, it’s to just answer the f’n questions.
Reference Article: https://openai.com/index/inside-our-in-house-data-agent/
Jorge Torres is the Co-founder and CEO of MindsDB. He writes about the intersection of AI, data infrastructure, and the decisions technology leaders actually have to make. This is the second installment of Thoughts on AI for Tech Leaders series.
When the company building AGI can't answer simple questions about itself, maybe the BIG problem is no longer intelligence, but the 15 tools between you and the answers?
OpenAI recently published a detailed account of Kepler, their internal AI data agent. It's a fascinating piece; the kind of "here's how the sausage we made that you can’t buy was made". I'd encourage everyone to read it. The article is, at its core, a confession.
Think about this: The company building the most advanced AI on the planet, the one with GPT-5.whatever humming away in its data centers, couldn't answer the question "How many ChatGPT Pro users are in France?" without sending analysts on an archaeological expedition across 70,000 datasets, 15 different tools, and troves of data. A question that should take seconds to minutes required, in their words, extended Slack conversations and sometimes meetings just to figure out how to access the data.
Let that marinate. Not "How do we achieve artificial general intelligence." Not "How do we align superintelligent systems with human values," but “How many paying customers do we have in a given location?”
Terrifying, right? Because if OpenAI (with functionally unlimited cash, engineering talent, and the most powerful language models ever created) needed to build a bespoke, non-commercializable internal tool to answer basic business questions from their own data...you must be wondering: what chance does your company have, with a stressful Jira board and a data team that's already three sprints behind?
The Diagnosis Is Universal. The Prescription Is Not.
To their credit, OpenAI didn't just build their internal tool and call it a day. They articulated why this problem is so hard, and their diagnosis reads like a clinical description of every enterprise data environment I've ever encountered.
The data is everywhere and nowhere. It lives in warehouses, lakes, SaaS platforms, spreadsheets that someone named "FINAL_v3_actually_final.xlsx," and the institutional memory of that one analyst who's been there since the seed round. Getting a coherent answer means stitching together fragments from systems that were never designed to talk to each other. It's not a data problem. It's a Babel problem.
Correct SQL is a miracle, not a given. OpenAI's team pointed out that even after you find the right tables, generating accurate queries is treacherous. Many-to-many joins. Filter pushdown errors. Unhandled nulls. Any one of these can silently produce results that are wrong by an order of magnitude. Their exact words: "Missing one nuance can be catastrophic when making important business decisions." This is a company that employs some of the best engineers alive, saying, "SQL is hard, and our people get it wrong." If your response to that is "well, our analysts don't make those mistakes," I'd gently suggest you might just not be catching them.
Context lives in the hallways, not the schemas. Two tables can look identical in structure and mean completely different things. One tracks all user traffic. The other tracks only first-party ChatGPT traffic. The difference between them? It's buried in a Slack thread from 2023, a Notion page three people have bookmarked, and the verbal institutional knowledge of someone who may or may not still work there. No amount of column metadata is going to surface that distinction. You need a system that understands the meaning of data, not just its shape.
OpenAI's answer was an internal tool: a dedicated internal agent powered by GPT-5.2, combining RAG over metadata, live warehouse queries, integration with Slack and Google Docs and Notion for institutional context, a memory system for continuous improvement, and codex tests for validation. And, unfortunately for you, it took a team of world-class engineers that most can’t afford or convince to join you unless you are the hottest of the AI companies, and an extended build-and-iterate cycle. Anyway, it covers the full analytics workflow: discovery, SQL generation, report publishing. It's available to OpenAI employees through Slack, a web interface, and their IDEs.
It is, by any measure, a serious piece of engineering.
It is also explicitly not for sale. OpenAI has stated they have no plans to commercialize it.
So: their article? A definitive diagnosis of why enterprise data is broken, paired with a solution that exactly zero other companies on Earth can use. Helpful. right?
The Part Where I Point Out That You, Too, Can Solve This
Well, luckily for all of you, there is Minds Enterprise by MindsDB.
Now, I know and I realize this is where yours truly, the CEO of MindsDB, tells you that our soup cures your illness, and you're calibrating your skepticism accordingly. Fair! But stay with me, because the architecture of the solution and the principles OpenAI validated with their not-for-sale internal tool are the same principles that drove our solution (Minds), and therefore are available to anyone who isn't OpenAI. So yes, I invite you to go ahead and try Minds.
I am not saying this just because we have been plumbers of data for AI since forever, and we have built the most widely-deployed AI Query engine in the world (https://github.com/mindsdb/mindsdb), but because we have been working on these problems for such a long time, that my emotional therapist knows them by heart, and because we have known they are very painful, we have built a solution that has matured for multiple years now. Let me walk you through it:
The Babel problem. OpenAI had to build custom integrations for their internal data systems. Every company that tries to replicate Kepler will face the same integration tax, and most will abandon the project when they realize the plumbing alone takes longer than the AI part. Minds connects to over 200 data sources natively: Databases, SaaS applications, file systems… Structured, unstructured, the kind of data that defies categorization. No data movement. No ETL pipelines. Your data stays where it is, and Minds federates across all of it. That's not a feature list — it's the difference between a project that ships and one that dies in integration hell.
The SQL accuracy problem. Kepler uses RAG over metadata to understand what tables mean, then generates SQL that accounts for the treacherous edge cases OpenAI described. Minds does the same thing, but combines parametric search (text-to-SQL) with semantic search (RAG), retaining the precision of SQL. The distinction matters: Minds doesn't just translate your question into SQL and hope for the best. It reasons about how to get the right answer, which is possible if you can do structured and unstructured queries in the same language, and the reason why we extended the SQL language to do that.
The context problem. OpenAI invested heavily in grounding Kepler with institutional knowledge — metric definitions, product context, the kind of nuance that separates a correct answer from a technically-valid-but-wrong one. Their team noted that context gets you 80–90% of the way there, but the final corrections require memory. Minds ships with Knowledge Bases that index massive volumes of structured and unstructured data, and you can embed your business rules, metric definitions, and domain context directly. It's not a chatbot stapled to a database. It's a system that learns what your data means.
The trust problem. This is the one that matters most, and it's the one most AI analytics tools get catastrophically wrong. If you can't see how an AI arrived at an answer, you can't verify it, defend it in a board meeting, or explain it to a regulator. Kepler's article gestures at this but doesn't elaborate. Minds makes it explicit: every answer comes with a visible chain of thought: what data was selected. From which source. How it informed the response. The reasoning is logged and observable. Not because transparency is a nice feature, but because in enterprise analytics, an answer you can't audit is worse than no answer at all.
When 'We'll Get Back to You Next Week' Becomes a Competitive Disadvantage
Here's the part that is very exciting: OpenAI's data team reported that their analysts were spending enormous amounts of time on what should be routine questions. Their internal agent (Kepler) brought that down dramatically. At MindsDB, we see the same pattern with our customers: what used to take an analyst five days—building a dashboard, extracting insights from raw data across multiple sources—takes minutes with Minds.
Five days to five minutes. That's not an incremental improvement. That's the difference between "we'll get back to you next week" and "here's the answer, and here's exactly how I got it." That's the difference between data-informed decisions and decisions that happen to have data attached retroactively.
Gartner predicts 40% of enterprise applications will embed AI agents by the end of 2026. Databricks reports 327% growth in multi-agent workflows. These aren't predictions anymore — they're deadlines. And if the most sophisticated AI company in the world needed a purpose-built data agent to make sense of its own information, that's not a niche use case. That's a universal requirement.
Conclusion
You don't need to be OpenAI to have OpenAI's data problems. You just need data, questions, and not enough hours in the day. Which, last time I checked, describes every company on Earth.
OpenAI built their internal agent (Kepler) because they had to. Because even with the best models, the best engineers, and functionally unlimited compute and money, data fragmentation, SQL complexity, and missing context made their own data almost unusable for basic business questions. They spent years solving it.
The architecture they described: federated queries, metadata grounding, institutional context, transparent reasoning, conversational exploration, continuous learning(!) isn't novel to us. It's a validation of what we've been building in the open, as a product, for years.
The difference? Well, you cannot buy their internal agent; it is tailor-made for OpenAI and not for sale, but you can use Minds. It deploys anywhere: any cloud, on-premises, or serverlessly in MindsDB's cloud. It serves not just data scientists, but anyone in finance, marketing, operations, or customer success who has a question and doesn't want to wait five days for the answer. Like our CRO often explains: Minds’ job is simple, it’s to just answer the f’n questions.
Reference Article: https://openai.com/index/inside-our-in-house-data-agent/
Jorge Torres is the Co-founder and CEO of MindsDB. He writes about the intersection of AI, data infrastructure, and the decisions technology leaders actually have to make. This is the second installment of Thoughts on AI for Tech Leaders series.
Products
Open Source
© 2026 All rights reserved by MindsDB.

Start conversational analytics with MindsDB
Production-ready infrastructure for agentic analytics
Start conversational analytics with MindsDB
Production-ready infrastructure for agentic analytics

Products
Open Source
© 2026 All rights reserved by MindsDB.

Products
Open Source
© 2026 All rights reserved by MindsDB.
Start conversational analytics with MindsDB
Production-ready infrastructure for agentic analytics