MindsDB Product Updates - January 2026

Chandre Van Der Westhuizen, Community & Marketing Co-ordinator at MindsDB

January 2026 brings a wide range of improvements across MindsDB, with a strong focus on stability, performance, and making everyday workflows smoother for developers and data teams. This month’s updates include meaningful enhancements to Knowledge Bases, deeper and more secure integrations, expanded SQL capabilities, and a long list of reliability and quality-of-life fixes across the platform.
From better handling of edge cases and cleaner database behavior to faster vector operations, improved deployments, and clearer documentation, these updates are designed to help you build and operate AI-powered analytics with more confidence and less friction. Below is a detailed look at what’s new and improved in MindsDB this month.
Knowledge Bases
This product update for Knowledge Bases brings a focus on clarity, stability, and data integrity. Error messages are now more descriptive when data is inserted into a non-existing Knowledge Base, making it easier to understand what went wrong and how to fix it. Improvements on cleanup logic has been made so that when a Knowledge Base is removed, any shared PGVector tables are automatically deleted, helping keep your database consistent and free of orphaned data.
To prevent issues during setup, MindsDB now validates vector dimensions in existing vector tables when creating a Knowledge Base. This ensures that embeddings are compatible from the start and avoids hard-to-debug runtime errors later on. MindsDB enhanced how it handles edge cases by safely supporting NaN values when inserting data into a Knowledge Base, reducing the risk of failures caused by null or invalid inputs.
On the platform side, we’ve upgraded our Mintlify documentation version, enabling a more refined and performant MindsDB Library experience. This update brings better performance and a smoother developer experience when browsing and using our documentation about Knowledge Bases.
Our team introduced more flexibility when working with MySQL. The row count setting in the MySQL data connector is now optional, giving users more control over how they configure their connections and making MindsDB easier to adapt to different database setups.
Finally, we’ve removed unnecessary associated tables and fixed issues related to non-existing column references. These cleanups improve overall system reliability and ensure more predictable behavior when working with complex schemas.

Integrations
The MongoDB renderer has been upgraded to provide more robust functionality and improved handling of complex data structures, resulting in a smoother experience when working with MongoDB-backed workloads.
We’re also excited to introduce MindsDB Lite, a compact and optimized version of MindsDB designed for faster installs and a smaller footprint. This makes it easier to get started with MindsDB, especially for developers who want a lightweight setup without sacrificing core capabilities.
For Snowflake users, we’ve expanded both security and analytical capabilities. A new key-value authentication option is now available, offering an additional and more flexible method to securely connect to Snowflake. Support has been added for Snowflake embeddings, enabling machine learning models to better understand semantic relationships and complex patterns directly within your Snowflake data.
On the performance side, we’ve introduced a new FAISS handler with a flat index, significantly improving the speed and accuracy of vector similarity search and clustering. This enhancement enables faster, more precise retrieval of relevant data, especially for large-scale vector workloads. You can see this in action in our latest blog, AI Knowledge Bases at Scale: Discovering Key Analytics Insights in Massive Data Archives.
We’ve also made deployment more consistent and predictable. A new Docker main dependencies setup has been introduced, along with a dedicated Snowflake image, simplifying deployments across environments. In addition, we’ve streamlined deployment and testing workflows to reduce friction and improve overall efficiency.
Finally, to maintain high quality in production, unit and integration tests are now included as part of the production deployment process. This ensures changes are thoroughly validated before going live, helping preserve stability and reliability across releases.

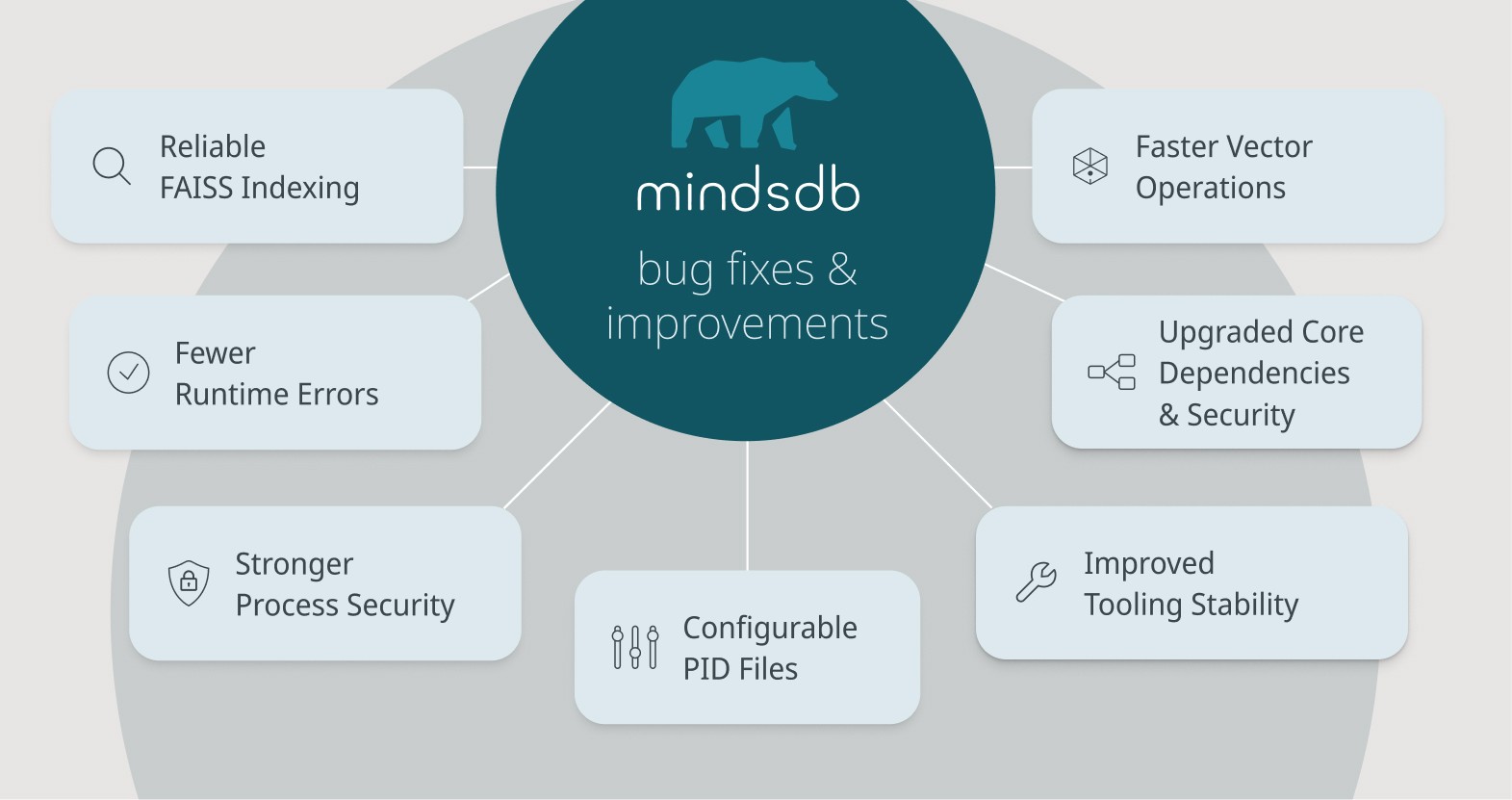
Bug Fixes and Improvements
This release includes a broad set of improvements aimed at making MindsDB more secure, stable, and predictable in day-to-day use. We’ve enhanced log handling to automatically hide sensitive information, helping protect credentials and other confidential data during debugging and monitoring. Several issues that could cause unnecessary warnings or errors have also been resolved, including bugs related to non-existent extras, service file reads and deletes, and REST parameters for JSON variables.
We’ve addressed a number of usability and reliability issues across the platform. A bug that prevented MindsDB Editor tabs from loading correctly has been fixed, along with issues around case sensitivity in Common Table Expressions (CTEs). Our team added more useful information to PID files and made their contents configurable, giving operators better visibility and control when running MindsDB in production environments.
MindsDB delivers a more stable and efficient experience across core functionality. This includes smoother startup behavior, fewer runtime interruptions, and improved handling of edge cases that previously caused avoidable errors.
Project documentation and dependencies have been greatly enhanced. The filelock dependency has been upgraded from version 3.18.0 to 3.20.1, strengthening protection against multi-process race conditions and improving overall security. This update has also been reflected in the project requirements.
On the performance and tooling side, the Faiss handler has been fixed to correctly use a flat index, ensuring more efficient and reliable vector operations. We’ve also upgraded our Mintlify documentation tooling for better performance and stability. In addition, the ImportError triggered by the --load-tokenizer option is now handled gracefully, preventing unnecessary disruptions during operation.
Finally, we’ve streamlined development and testing workflows by skipping tests when only asset changes are detected, saving time and resources without compromising quality. An important fix was also introduced to ensure schemas are correctly applied when provided through connection arguments, improving data flow reliability and reducing friction when configuring integrations.
SQL Operations
This update brings several improvements for Snowflake users, along with enhancements to SQL compatibility and query reliability. We’ve added support for Snowflake key-value authentication, giving users an additional and more flexible way to securely connect to their Snowflake databases. This new option improves both security and ease of setup, especially in environments with stricter authentication requirements.
We’ve improved how MindsDB handles SQL queries involving complex column names. Queries that reference columns containing spaces in their names are now handled correctly, eliminating errors that previously occurred in these cases. This makes SQL operations more robust and allows MindsDB to work more smoothly with a wider range of existing schemas.
On the SQL parsing side, a parser dependency upgrade introduces support for UNION within IN clauses, expanding query expressiveness and improving compatibility with more advanced SQL patterns.
Finally, we’ve added support for Snowflake embeddings, enabling richer semantic analysis directly on Snowflake data. With this capability, machine learning models can better understand relationships and patterns within your datasets, unlocking more advanced analytical and AI-driven use cases.

Documentation
Database naming conventions are now more clearly documented, providing better guidance and reducing confusion when working across different data sources.
To support visual learners, we’ve added a new Knowledge Bases walkthrough video to the documentation. This gives users a step-by-step visual overview of how Knowledge Bases work and how to use them effectively in real-world scenarios.
Our documentation has expanded around integrations by clearly outlining test coverage for verified handlers. This makes it easier to understand which integrations and actions are fully tested and supported, helping users make informed decisions when building on MindsDB.
The documentation for the HubSpot handler has been updated with clearer and more accurate instructions, improving usability and reducing friction during setup and configuration. In addition, the GitHub README was refreshed to improve clarity and navigation. While that specific update was later reverted to make room for further improvements, it reflects our ongoing effort to keep MindsDB documentation current, accurate, and easy to follow.

Additional Updates
We’ve improved how MindsDB reports system health by fixing an issue where health checks could time out when API workers were under heavy load. With this update, health checks now more accurately reflect the true state of the APIs, giving operators and monitoring systems more reliable signals during peak usage.
MindsDB has tightened security and reliability in our testing environment by updating permissions in the tests_unit.yml configuration. This change helps ensure tests run in a more secure setup and that results better reflect real-world conditions.
Finally, we’ve upgraded the numpy dependency to version 2 and above. This update delivers performance improvements and increased stability across numerical operations, helping MindsDB run more efficiently under the hood.
Conclusion
This release reflects our continued focus on making MindsDB more reliable, flexible, and production-ready as teams scale AI-driven analytics across real-world data. The improvements in Knowledge Bases, integrations, SQL operations, and documentation aim to reduce friction, prevent common pitfalls, and give users more control and clarity at every stage—from setup to production.
As always, we’re committed to improving MindsDB based on real usage and community feedback. We’ll continue refining performance, security, and developer experience in the months ahead. If you’d like to explore these updates in more detail, check out the latest documentation or join the conversation in our slack community. Explore the full Release Notes here.
January 2026 brings a wide range of improvements across MindsDB, with a strong focus on stability, performance, and making everyday workflows smoother for developers and data teams. This month’s updates include meaningful enhancements to Knowledge Bases, deeper and more secure integrations, expanded SQL capabilities, and a long list of reliability and quality-of-life fixes across the platform.
From better handling of edge cases and cleaner database behavior to faster vector operations, improved deployments, and clearer documentation, these updates are designed to help you build and operate AI-powered analytics with more confidence and less friction. Below is a detailed look at what’s new and improved in MindsDB this month.
Knowledge Bases
This product update for Knowledge Bases brings a focus on clarity, stability, and data integrity. Error messages are now more descriptive when data is inserted into a non-existing Knowledge Base, making it easier to understand what went wrong and how to fix it. Improvements on cleanup logic has been made so that when a Knowledge Base is removed, any shared PGVector tables are automatically deleted, helping keep your database consistent and free of orphaned data.
To prevent issues during setup, MindsDB now validates vector dimensions in existing vector tables when creating a Knowledge Base. This ensures that embeddings are compatible from the start and avoids hard-to-debug runtime errors later on. MindsDB enhanced how it handles edge cases by safely supporting NaN values when inserting data into a Knowledge Base, reducing the risk of failures caused by null or invalid inputs.
On the platform side, we’ve upgraded our Mintlify documentation version, enabling a more refined and performant MindsDB Library experience. This update brings better performance and a smoother developer experience when browsing and using our documentation about Knowledge Bases.
Our team introduced more flexibility when working with MySQL. The row count setting in the MySQL data connector is now optional, giving users more control over how they configure their connections and making MindsDB easier to adapt to different database setups.
Finally, we’ve removed unnecessary associated tables and fixed issues related to non-existing column references. These cleanups improve overall system reliability and ensure more predictable behavior when working with complex schemas.
Integrations
The MongoDB renderer has been upgraded to provide more robust functionality and improved handling of complex data structures, resulting in a smoother experience when working with MongoDB-backed workloads.
We’re also excited to introduce MindsDB Lite, a compact and optimized version of MindsDB designed for faster installs and a smaller footprint. This makes it easier to get started with MindsDB, especially for developers who want a lightweight setup without sacrificing core capabilities.
For Snowflake users, we’ve expanded both security and analytical capabilities. A new key-value authentication option is now available, offering an additional and more flexible method to securely connect to Snowflake. Support has been added for Snowflake embeddings, enabling machine learning models to better understand semantic relationships and complex patterns directly within your Snowflake data.
On the performance side, we’ve introduced a new FAISS handler with a flat index, significantly improving the speed and accuracy of vector similarity search and clustering. This enhancement enables faster, more precise retrieval of relevant data, especially for large-scale vector workloads. You can see this in action in our latest blog, AI Knowledge Bases at Scale: Discovering Key Analytics Insights in Massive Data Archives.
We’ve also made deployment more consistent and predictable. A new Docker main dependencies setup has been introduced, along with a dedicated Snowflake image, simplifying deployments across environments. In addition, we’ve streamlined deployment and testing workflows to reduce friction and improve overall efficiency.
Finally, to maintain high quality in production, unit and integration tests are now included as part of the production deployment process. This ensures changes are thoroughly validated before going live, helping preserve stability and reliability across releases.
Bug Fixes and Improvements
This release includes a broad set of improvements aimed at making MindsDB more secure, stable, and predictable in day-to-day use. We’ve enhanced log handling to automatically hide sensitive information, helping protect credentials and other confidential data during debugging and monitoring. Several issues that could cause unnecessary warnings or errors have also been resolved, including bugs related to non-existent extras, service file reads and deletes, and REST parameters for JSON variables.
We’ve addressed a number of usability and reliability issues across the platform. A bug that prevented MindsDB Editor tabs from loading correctly has been fixed, along with issues around case sensitivity in Common Table Expressions (CTEs). Our team added more useful information to PID files and made their contents configurable, giving operators better visibility and control when running MindsDB in production environments.
MindsDB delivers a more stable and efficient experience across core functionality. This includes smoother startup behavior, fewer runtime interruptions, and improved handling of edge cases that previously caused avoidable errors.
Project documentation and dependencies have been greatly enhanced. The filelock dependency has been upgraded from version 3.18.0 to 3.20.1, strengthening protection against multi-process race conditions and improving overall security. This update has also been reflected in the project requirements.
On the performance and tooling side, the Faiss handler has been fixed to correctly use a flat index, ensuring more efficient and reliable vector operations. We’ve also upgraded our Mintlify documentation tooling for better performance and stability. In addition, the ImportError triggered by the --load-tokenizer option is now handled gracefully, preventing unnecessary disruptions during operation.
Finally, we’ve streamlined development and testing workflows by skipping tests when only asset changes are detected, saving time and resources without compromising quality. An important fix was also introduced to ensure schemas are correctly applied when provided through connection arguments, improving data flow reliability and reducing friction when configuring integrations.
SQL Operations
This update brings several improvements for Snowflake users, along with enhancements to SQL compatibility and query reliability. We’ve added support for Snowflake key-value authentication, giving users an additional and more flexible way to securely connect to their Snowflake databases. This new option improves both security and ease of setup, especially in environments with stricter authentication requirements.
We’ve improved how MindsDB handles SQL queries involving complex column names. Queries that reference columns containing spaces in their names are now handled correctly, eliminating errors that previously occurred in these cases. This makes SQL operations more robust and allows MindsDB to work more smoothly with a wider range of existing schemas.
On the SQL parsing side, a parser dependency upgrade introduces support for UNION within IN clauses, expanding query expressiveness and improving compatibility with more advanced SQL patterns.
Finally, we’ve added support for Snowflake embeddings, enabling richer semantic analysis directly on Snowflake data. With this capability, machine learning models can better understand relationships and patterns within your datasets, unlocking more advanced analytical and AI-driven use cases.
Documentation
Database naming conventions are now more clearly documented, providing better guidance and reducing confusion when working across different data sources.
To support visual learners, we’ve added a new Knowledge Bases walkthrough video to the documentation. This gives users a step-by-step visual overview of how Knowledge Bases work and how to use them effectively in real-world scenarios.
Our documentation has expanded around integrations by clearly outlining test coverage for verified handlers. This makes it easier to understand which integrations and actions are fully tested and supported, helping users make informed decisions when building on MindsDB.
The documentation for the HubSpot handler has been updated with clearer and more accurate instructions, improving usability and reducing friction during setup and configuration. In addition, the GitHub README was refreshed to improve clarity and navigation. While that specific update was later reverted to make room for further improvements, it reflects our ongoing effort to keep MindsDB documentation current, accurate, and easy to follow.
Additional Updates
We’ve improved how MindsDB reports system health by fixing an issue where health checks could time out when API workers were under heavy load. With this update, health checks now more accurately reflect the true state of the APIs, giving operators and monitoring systems more reliable signals during peak usage.
MindsDB has tightened security and reliability in our testing environment by updating permissions in the tests_unit.yml configuration. This change helps ensure tests run in a more secure setup and that results better reflect real-world conditions.
Finally, we’ve upgraded the numpy dependency to version 2 and above. This update delivers performance improvements and increased stability across numerical operations, helping MindsDB run more efficiently under the hood.
Conclusion
This release reflects our continued focus on making MindsDB more reliable, flexible, and production-ready as teams scale AI-driven analytics across real-world data. The improvements in Knowledge Bases, integrations, SQL operations, and documentation aim to reduce friction, prevent common pitfalls, and give users more control and clarity at every stage—from setup to production.
As always, we’re committed to improving MindsDB based on real usage and community feedback. We’ll continue refining performance, security, and developer experience in the months ahead. If you’d like to explore these updates in more detail, check out the latest documentation or join the conversation in our slack community. Explore the full Release Notes here.
Products
Open Source
© 2026 All rights reserved by MindsDB.

Start conversational analytics with MindsDB
Production-ready infrastructure for agentic analytics
Start conversational analytics with MindsDB
Production-ready infrastructure for agentic analytics

Products
Open Source
© 2026 All rights reserved by MindsDB.

Products
Open Source
© 2026 All rights reserved by MindsDB.
Start conversational analytics with MindsDB
Production-ready infrastructure for agentic analytics