
Introducing MindsDB’s Hybrid Search: Find What Matters in a Sea of Enterprise Data

Chandre Van Der Westhuizen, Community & Marketing Co-ordinator at MindsDB

As large language models (LLMs) and vector search become increasingly common in enterprise AI stacks, one of the quiet but persistent challenges is precision. Semantic search excels at retrieving conceptually similar content, but it can fail when exact keyword matching is essential—such as for product SKUs, codes, acronyms, or names that aren’t semantically rich. Conversely, keyword search provides precision but lacks the contextual understanding needed for high-level queries.
MindsDB’s new Hybrid Search feature addresses this challenge by merging symbolic (keyword-based) and sub-symbolic (embedding-based) retrieval mechanisms into a single, tunable interface—directly within your SQL queries. This integration provides both coverage and control, allowing practitioners to optimize the relevance of AI-generated responses without needing to orchestrate external retrieval frameworks.
The Limitations of Pure Semantic Search
Semantic search is used to provide content related to what you are searching and is great at understanding the meaning behind your words, but not always the exact details you are looking for.
Let’s take an example of trying to search for specific documents for a customer name, 'Megacorp' - using semantic search will provide general 'Megacorp' data and product pages instead of the exact content you are looking for. That’s because many semantic search systems don’t focus on exact matches.
Keyword-based search will provide exact matches of 'Megacorp' in content, but miss out on crucial context and related documents that may not have an exact match.
In environments where acronyms, custom codes, specific customer information and product IDs are just as important as the topic, this can lead to wrong results or missing information.
Why Hybrid Search?
Hybrid search finds information using both meaning and exact word matches for more accurate results. If you are looking for a specific document or information about customers or products, using solely semantic search will provide general information when retrieving details about customers and products, and using keyword search with a customer ID or product ID might find it, but list it far down the results.
Hybrid Search uses both methods at the same time, then combines and sorts the results so you get the most accurate and useful answers first.
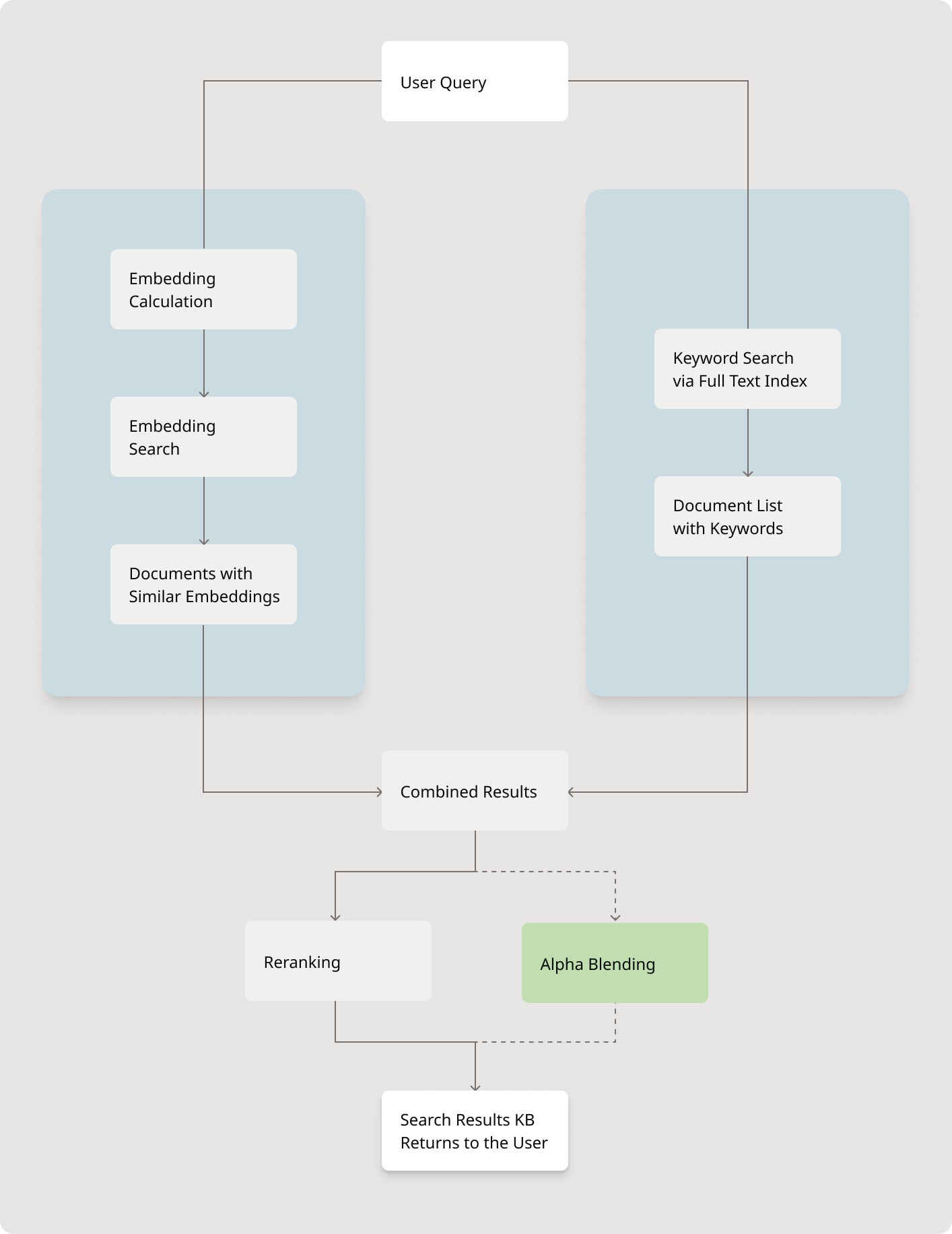
How It Works (Without Overcomplicating It)
When you submit a query, MindsDB’s Hybrid Search kicks off two processes at once:
Semantic Search: Converts your query into an embedding (a vector) and finds similar documents based on meaning.
Keyword Search: Looks for exact term matches using a full-text index, optimized for performance using an inverted index structure—ideal for pinpointing acronyms, ticket numbers, or product codes.
Each knowledge base maintains its own semantic embeddings and full-text index. This ensures high performance and accuracy without needing to sync multiple systems.
Bringing the Results Together
Once both search processes return results, they’re combined and passed through a reranker. This step is key—it reorders the documents based on overall relevance, considering both types of matches.
There are two ways reranking can happen:
Using a reranking model built into the knowledge base
This model learns how to balance keyword and semantic relevance to return the best results.Using the
hybrid_search_alphaparameter
This gives you full control over weighting. Want keyword matches to dominate? Setalphacloser to 0. Prefer semantic understanding? Move it toward 1.
What About Performance?
Reranking can be computationally expensive, especially at scale. That’s why MindsDB uses smart heuristics—like BM25, a well-established ranking function that scores documents based on how often a keyword appears in them and how rare that keyword is across the entire knowledge base. This is used only by the alpha reranking that is available with hybrid search.
By applying BM25 up front, Hybrid Search narrows down the set of documents before reranking, which keeps things fast without sacrificing quality.
Example Use Case : Verifying The Sales Cycle Of Prospects
Imagine you are a sales manager and would like to retrieve details of a specific prospect, called Young and Sons, and their interactions with the team to see where they are in the sales cycle. To do that, you will have to search for that information spread across two tables in a database. Let’s explore how you will be able to retrieve details with Hybrid search.
Get started with accessing MindsDB through local Docker Installation, MindsDB’s Extension via Docker Desktop and AWS Marketplace.
Connect your database to MindsDB using the CREATE DATABASE statement.
CREATE DATABASE sales_manager_data WITH ENGINE = 'postgres', PARAMETERS = { "user": "demo_user", "password": "demo_password", "host": "samples.mindsdb.com", "port": "5432", "database": "sales_manager_data" };
CREATE DATABASE sales_manager_data WITH ENGINE = 'postgres', PARAMETERS = { "user": "demo_user", "password": "demo_password", "host": "samples.mindsdb.com", "port": "5432", "database": "sales_manager_data" };
CREATE DATABASE sales_manager_data WITH ENGINE = 'postgres', PARAMETERS = { "user": "demo_user", "password": "demo_password", "host": "samples.mindsdb.com", "port": "5432", "database": "sales_manager_data" };
CREATE DATABASE sales_manager_data WITH ENGINE = 'postgres', PARAMETERS = { "user": "demo_user", "password": "demo_password", "host": "samples.mindsdb.com", "port": "5432", "database": "sales_manager_data" };
As Hybrid Search is only available for knowledge bases backed by a PGVector engine (PostgreSQL with vector extension), we will have to connect PGVector as a database to use as a storage table.
CREATE DATABASE pvec WITH ENGINE = 'pgvector', PARAMETERS = { "host": "127.0.0.1", "port": 5432, "database": "postgres", "user": "postgres", "password": "password" };
CREATE DATABASE pvec WITH ENGINE = 'pgvector', PARAMETERS = { "host": "127.0.0.1", "port": 5432, "database": "postgres", "user": "postgres", "password": "password" };
CREATE DATABASE pvec WITH ENGINE = 'pgvector', PARAMETERS = { "host": "127.0.0.1", "port": 5432, "database": "postgres", "user": "postgres", "password": "password" };
CREATE DATABASE pvec WITH ENGINE = 'pgvector', PARAMETERS = { "host": "127.0.0.1", "port": 5432, "database": "postgres", "user": "postgres", "password": "password" };
The Knowledge Base can be created using the CREATE KNOWLEDGE_BASE statement.
CREATE KNOWLEDGE_BASE sales_prospects_kb USING embedding_model = { "provider": "openai", "model_name" : "text-embedding-3-large", "api_key": "sk-xxxxxx" }, reranking_model = { "provider": "openai", "model_name": "gpt-4o", "api_key": "sk-xxxxx" }, storage = pvec.storage_table, metadata_columns = ['created_at', 'company'], content_columns = ['call_summary', 'key_points', 'next_steps'], id_column = 'id';
CREATE KNOWLEDGE_BASE sales_prospects_kb USING embedding_model = { "provider": "openai", "model_name" : "text-embedding-3-large", "api_key": "sk-xxxxxx" }, reranking_model = { "provider": "openai", "model_name": "gpt-4o", "api_key": "sk-xxxxx" }, storage = pvec.storage_table, metadata_columns = ['created_at', 'company'], content_columns = ['call_summary', 'key_points', 'next_steps'], id_column = 'id';
CREATE KNOWLEDGE_BASE sales_prospects_kb USING embedding_model = { "provider": "openai", "model_name" : "text-embedding-3-large", "api_key": "sk-xxxxxx" }, reranking_model = { "provider": "openai", "model_name": "gpt-4o", "api_key": "sk-xxxxx" }, storage = pvec.storage_table, metadata_columns = ['created_at', 'company'], content_columns = ['call_summary', 'key_points', 'next_steps'], id_column = 'id';
CREATE KNOWLEDGE_BASE sales_prospects_kb USING embedding_model = { "provider": "openai", "model_name" : "text-embedding-3-large", "api_key": "sk-xxxxxx" }, reranking_model = { "provider": "openai", "model_name": "gpt-4o", "api_key": "sk-xxxxx" }, storage = pvec.storage_table, metadata_columns = ['created_at', 'company'], content_columns = ['call_summary', 'key_points', 'next_steps'], id_column = 'id';
The Knowledge base was provided with the name sales_prospects_kb, an embedding mode OpenAI’s text-embedding-3-large model was used, a reranking model where OpenAI’s gpt-4o model was used, and column names for where data will be inserted. If you would like to learn more about the syntax used for creating knowledge bases, you can visit our Knowledge Base documentation
The below explores the various parameters in the Knowledge Base syntax:
embedding model- The embedding model is a required component of the knowledge base. It stores specifications of the embedding model to be used.
reranking model- The reranking model is an optional component of the knowledge base. It stores specifications of the reranking model to be used.
metadata_columns- The data inserted into the knowledge base can be classified as metadata, which enables users to filter the search results using defined data fields.
content_columns- The data inserted into the knowledge base can be classified as content, which is embedded by the embedding model and stored in the underlying vector store.
id_column- The ID column uniquely identifies each source data row in the knowledge base. It is an optional parameter. If provided, this parameter is a string that contains the source data ID column name. If not provided, it is generated from the hash of the content columns.
To check if the Knowledge Base was successfully created, you can run the DESCRIBE KNOWLEDGE BASE statement.
Once the Knowledge Base is successfully created, it is ready for the data to be inserted by using the INSERT INTO statement.
INSERT INTO sales_prospects_kb SELECT id, created_at, company, call_summary, key_points, next_steps FROM sales_manager_data.call_summaries;
INSERT INTO sales_prospects_kb SELECT id, created_at, company, call_summary, key_points, next_steps FROM sales_manager_data.call_summaries;
INSERT INTO sales_prospects_kb SELECT id, created_at, company, call_summary, key_points, next_steps FROM sales_manager_data.call_summaries;
INSERT INTO sales_prospects_kb SELECT id, created_at, company, call_summary, key_points, next_steps FROM sales_manager_data.call_summaries;
Once the data is inserted, you can query the Knowledge Base to see if the data was successfully inserted.
SELECT * from sales_prospects_kb;
SELECT * from sales_prospects_kb;
SELECT * from sales_prospects_kb;
SELECT * from sales_prospects_kb;
MindsDB allows you to evaluate your Knowledge Base with the EVALUATE KNOWLEDGE BASE statement, ensuring that you can trust your data.
Now the Hybrid Search feature can be implemented.
SELECT * FROM sales_prospects_my_kb WHERE content = 'Yound and Sons' AND hybrid_search = true AND hybrid_search_alpha = 0.8;
SELECT * FROM sales_prospects_my_kb WHERE content = 'Yound and Sons' AND hybrid_search = true AND hybrid_search_alpha = 0.8;
SELECT * FROM sales_prospects_my_kb WHERE content = 'Yound and Sons' AND hybrid_search = true AND hybrid_search_alpha = 0.8;
SELECT * FROM sales_prospects_my_kb WHERE content = 'Yound and Sons' AND hybrid_search = true AND hybrid_search_alpha = 0.8;
Let’s look at the parameters provided for the Hybrid search:
hybrid_search = truetells MindsDB to execute both semantic and keyword retrieval paths.hybrid_search_alphais a float between 0 and 1 that controls weighting:0.0= full reliance on keyword score1.0= pure semantic similarity0.5(default) = balanced combination
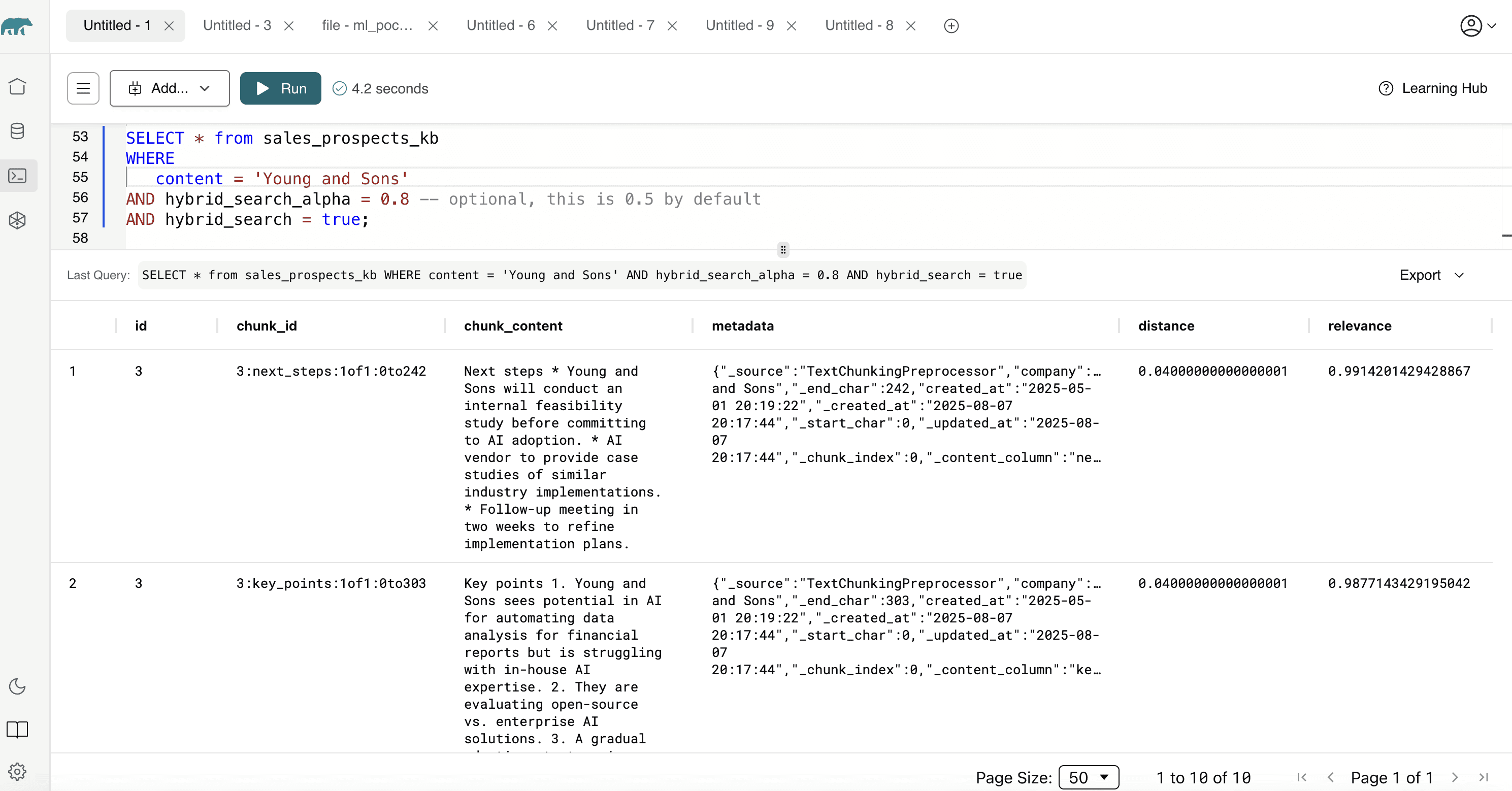
This query surface enables precise tuning of recall vs. precision, a tradeoff often hard-coded in other systems.Details about call summaries and next steps are provided for the prospect Young and Sons, and it can be seen where they are in the sales cycle enabling you to make decisions on the next course of action.
Knowledge bases in MindsDB give you the option to use a reranker—a tool that reorders results from both the semantic search and keyword search so the most relevant documents appear at the top. You can turn it on when accuracy is critical, or skip it if speed is more important.
If you’d rather not use the reranker, just set reranking = false. MindsDB will still merge the two result sets, but instead of reordering them with a model, it calculates a weighted average of two scores:
the semantic similarity score from the embedding search
the BM25 keyword relevance score from the full-text search
The result? You still get a balanced list of details, just without the extra processing step.
SELECT * from sales_prospects_kb WHERE content = 'Young and Sons' AND hybrid_search_alpha = 0.4 -- optional, this is 0.5 by default AND hybrid_search = true AND reranking = false;
SELECT * from sales_prospects_kb WHERE content = 'Young and Sons' AND hybrid_search_alpha = 0.4 -- optional, this is 0.5 by default AND hybrid_search = true AND reranking = false;
SELECT * from sales_prospects_kb WHERE content = 'Young and Sons' AND hybrid_search_alpha = 0.4 -- optional, this is 0.5 by default AND hybrid_search = true AND reranking = false;
SELECT * from sales_prospects_kb WHERE content = 'Young and Sons' AND hybrid_search_alpha = 0.4 -- optional, this is 0.5 by default AND hybrid_search = true AND reranking = false;
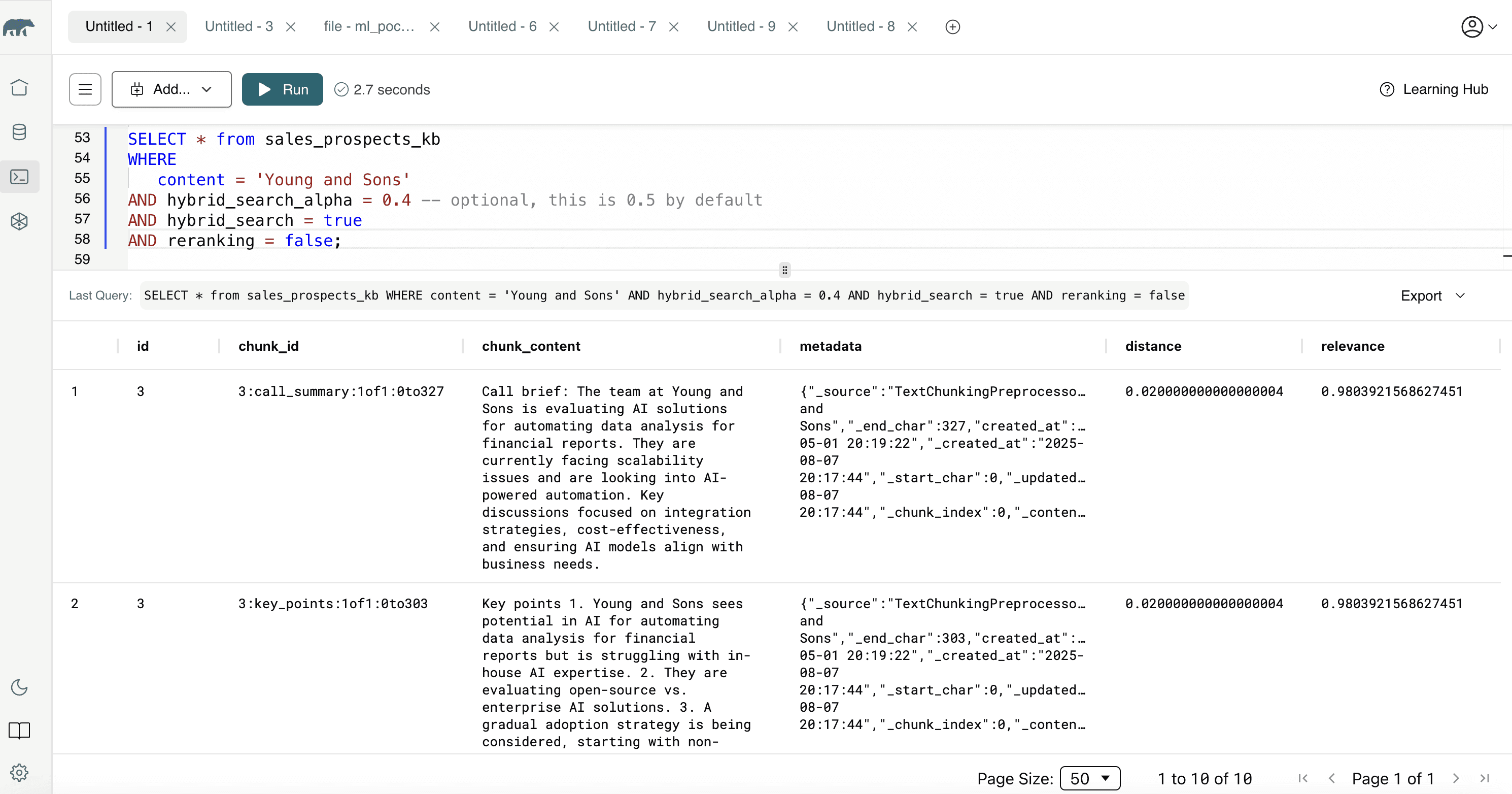
In this case, we’re emphasizing keyword relevance while skipping reranking—perfect if you already trust the scoring system.
MindsDB’s Hybrid Search feature gives you the flexibility to query how you think—sometimes that means searching for concepts, sometimes it means looking for exact strings. With both modes working together, you get grounded, accurate, and explainable results—without needing to duct-tape search layers together.
Why This Matters for Retrieval-Augmented Generation (RAG)
Hybrid Search plays a critical role in RAG pipelines, where grounding LLM outputs in verifiable context is essential.
LLMs will confidently generate text based on the documents retrieved. If retrieval is flawed—too fuzzy, too rigid, or incomplete—then hallucinations follow. Hybrid Search significantly reduces this risk by:
Ensuring factual grounding with token-aware retrieval
Improving contextual relevance with embedding-based search
Increasing trust with citation and score transparency via MindsDB's structured outputs
In short, it’s a step toward more explainable, controllable, and trustworthy LLM systems in production.

Use Cases That Benefit Most
Customer support assistants: Retrieve tickets by both content similarity and exact issue codes.
Legal or compliance review: Search for conceptually similar clauses while capturing precise statute references.
Product search: Surface items using descriptions and exact product IDs.
Internal documentation: Match user queries with acronyms and technical terms that embeddings alone might miss.
Why This Matters for Real Use Cases
Hybrid Search isn’t just a technical improvement—it’s a practical one. Here’s why:
Support teams can search using both error codes and natural language questions.
Legal teams can find exact clauses and related context in policy documents.
Product teams can locate features by keyword or thematic match.
Engineers can query internal docs using exact error strings and broader troubleshooting terms.
Closing Thoughts
Hybrid Search goes beyond a single feature—it reflects an evolving philosophy in AI system design: that language understanding and symbolic precision aren’t mutually exclusive. MindsDB has built this duality into its architecture in a way that’s accessible, tunable, and grounded in SQL—no need to wire up external vector databases or rerankers.
For AI engineers, data teams, and AI practitioners working on real-world LLM applications, this is a powerful addition to the toolbox—especially in domains where the cost of a misretrieved document is high.
You can read more in the official Hybrid Search documentation.
As large language models (LLMs) and vector search become increasingly common in enterprise AI stacks, one of the quiet but persistent challenges is precision. Semantic search excels at retrieving conceptually similar content, but it can fail when exact keyword matching is essential—such as for product SKUs, codes, acronyms, or names that aren’t semantically rich. Conversely, keyword search provides precision but lacks the contextual understanding needed for high-level queries.
MindsDB’s new Hybrid Search feature addresses this challenge by merging symbolic (keyword-based) and sub-symbolic (embedding-based) retrieval mechanisms into a single, tunable interface—directly within your SQL queries. This integration provides both coverage and control, allowing practitioners to optimize the relevance of AI-generated responses without needing to orchestrate external retrieval frameworks.
The Limitations of Pure Semantic Search
Semantic search is used to provide content related to what you are searching and is great at understanding the meaning behind your words, but not always the exact details you are looking for.
Let’s take an example of trying to search for specific documents for a customer name, 'Megacorp' - using semantic search will provide general 'Megacorp' data and product pages instead of the exact content you are looking for. That’s because many semantic search systems don’t focus on exact matches.
Keyword-based search will provide exact matches of 'Megacorp' in content, but miss out on crucial context and related documents that may not have an exact match.
In environments where acronyms, custom codes, specific customer information and product IDs are just as important as the topic, this can lead to wrong results or missing information.
Why Hybrid Search?
Hybrid search finds information using both meaning and exact word matches for more accurate results. If you are looking for a specific document or information about customers or products, using solely semantic search will provide general information when retrieving details about customers and products, and using keyword search with a customer ID or product ID might find it, but list it far down the results.
Hybrid Search uses both methods at the same time, then combines and sorts the results so you get the most accurate and useful answers first.
How It Works (Without Overcomplicating It)
When you submit a query, MindsDB’s Hybrid Search kicks off two processes at once:
Semantic Search: Converts your query into an embedding (a vector) and finds similar documents based on meaning.
Keyword Search: Looks for exact term matches using a full-text index, optimized for performance using an inverted index structure—ideal for pinpointing acronyms, ticket numbers, or product codes.
Each knowledge base maintains its own semantic embeddings and full-text index. This ensures high performance and accuracy without needing to sync multiple systems.
Bringing the Results Together
Once both search processes return results, they’re combined and passed through a reranker. This step is key—it reorders the documents based on overall relevance, considering both types of matches.
There are two ways reranking can happen:
Using a reranking model built into the knowledge base
This model learns how to balance keyword and semantic relevance to return the best results.Using the
hybrid_search_alphaparameter
This gives you full control over weighting. Want keyword matches to dominate? Setalphacloser to 0. Prefer semantic understanding? Move it toward 1.
What About Performance?
Reranking can be computationally expensive, especially at scale. That’s why MindsDB uses smart heuristics—like BM25, a well-established ranking function that scores documents based on how often a keyword appears in them and how rare that keyword is across the entire knowledge base. This is used only by the alpha reranking that is available with hybrid search.
By applying BM25 up front, Hybrid Search narrows down the set of documents before reranking, which keeps things fast without sacrificing quality.
Example Use Case : Verifying The Sales Cycle Of Prospects
Imagine you are a sales manager and would like to retrieve details of a specific prospect, called Young and Sons, and their interactions with the team to see where they are in the sales cycle. To do that, you will have to search for that information spread across two tables in a database. Let’s explore how you will be able to retrieve details with Hybrid search.
Get started with accessing MindsDB through local Docker Installation, MindsDB’s Extension via Docker Desktop and AWS Marketplace.
Connect your database to MindsDB using the CREATE DATABASE statement.
CREATE DATABASE sales_manager_data WITH ENGINE = 'postgres', PARAMETERS = { "user": "demo_user", "password": "demo_password", "host": "samples.mindsdb.com", "port": "5432", "database": "sales_manager_data" };
As Hybrid Search is only available for knowledge bases backed by a PGVector engine (PostgreSQL with vector extension), we will have to connect PGVector as a database to use as a storage table.
CREATE DATABASE pvec WITH ENGINE = 'pgvector', PARAMETERS = { "host": "127.0.0.1", "port": 5432, "database": "postgres", "user": "postgres", "password": "password" };
The Knowledge Base can be created using the CREATE KNOWLEDGE_BASE statement.
CREATE KNOWLEDGE_BASE sales_prospects_kb USING embedding_model = { "provider": "openai", "model_name" : "text-embedding-3-large", "api_key": "sk-xxxxxx" }, reranking_model = { "provider": "openai", "model_name": "gpt-4o", "api_key": "sk-xxxxx" }, storage = pvec.storage_table, metadata_columns = ['created_at', 'company'], content_columns = ['call_summary', 'key_points', 'next_steps'], id_column = 'id';
The Knowledge base was provided with the name sales_prospects_kb, an embedding mode OpenAI’s text-embedding-3-large model was used, a reranking model where OpenAI’s gpt-4o model was used, and column names for where data will be inserted. If you would like to learn more about the syntax used for creating knowledge bases, you can visit our Knowledge Base documentation
The below explores the various parameters in the Knowledge Base syntax:
embedding model- The embedding model is a required component of the knowledge base. It stores specifications of the embedding model to be used.
reranking model- The reranking model is an optional component of the knowledge base. It stores specifications of the reranking model to be used.
metadata_columns- The data inserted into the knowledge base can be classified as metadata, which enables users to filter the search results using defined data fields.
content_columns- The data inserted into the knowledge base can be classified as content, which is embedded by the embedding model and stored in the underlying vector store.
id_column- The ID column uniquely identifies each source data row in the knowledge base. It is an optional parameter. If provided, this parameter is a string that contains the source data ID column name. If not provided, it is generated from the hash of the content columns.
To check if the Knowledge Base was successfully created, you can run the DESCRIBE KNOWLEDGE BASE statement.
Once the Knowledge Base is successfully created, it is ready for the data to be inserted by using the INSERT INTO statement.
INSERT INTO sales_prospects_kb SELECT id, created_at, company, call_summary, key_points, next_steps FROM sales_manager_data.call_summaries;
Once the data is inserted, you can query the Knowledge Base to see if the data was successfully inserted.
SELECT * from sales_prospects_kb;
MindsDB allows you to evaluate your Knowledge Base with the EVALUATE KNOWLEDGE BASE statement, ensuring that you can trust your data.
Now the Hybrid Search feature can be implemented.
SELECT * FROM sales_prospects_my_kb WHERE content = 'Yound and Sons' AND hybrid_search = true AND hybrid_search_alpha = 0.8;
Let’s look at the parameters provided for the Hybrid search:
hybrid_search = truetells MindsDB to execute both semantic and keyword retrieval paths.hybrid_search_alphais a float between 0 and 1 that controls weighting:0.0= full reliance on keyword score1.0= pure semantic similarity0.5(default) = balanced combination
This query surface enables precise tuning of recall vs. precision, a tradeoff often hard-coded in other systems.Details about call summaries and next steps are provided for the prospect Young and Sons, and it can be seen where they are in the sales cycle enabling you to make decisions on the next course of action.
Knowledge bases in MindsDB give you the option to use a reranker—a tool that reorders results from both the semantic search and keyword search so the most relevant documents appear at the top. You can turn it on when accuracy is critical, or skip it if speed is more important.
If you’d rather not use the reranker, just set reranking = false. MindsDB will still merge the two result sets, but instead of reordering them with a model, it calculates a weighted average of two scores:
the semantic similarity score from the embedding search
the BM25 keyword relevance score from the full-text search
The result? You still get a balanced list of details, just without the extra processing step.
SELECT * from sales_prospects_kb WHERE content = 'Young and Sons' AND hybrid_search_alpha = 0.4 -- optional, this is 0.5 by default AND hybrid_search = true AND reranking = false;
In this case, we’re emphasizing keyword relevance while skipping reranking—perfect if you already trust the scoring system.
MindsDB’s Hybrid Search feature gives you the flexibility to query how you think—sometimes that means searching for concepts, sometimes it means looking for exact strings. With both modes working together, you get grounded, accurate, and explainable results—without needing to duct-tape search layers together.
Why This Matters for Retrieval-Augmented Generation (RAG)
Hybrid Search plays a critical role in RAG pipelines, where grounding LLM outputs in verifiable context is essential.
LLMs will confidently generate text based on the documents retrieved. If retrieval is flawed—too fuzzy, too rigid, or incomplete—then hallucinations follow. Hybrid Search significantly reduces this risk by:
Ensuring factual grounding with token-aware retrieval
Improving contextual relevance with embedding-based search
Increasing trust with citation and score transparency via MindsDB's structured outputs
In short, it’s a step toward more explainable, controllable, and trustworthy LLM systems in production.
Use Cases That Benefit Most
Customer support assistants: Retrieve tickets by both content similarity and exact issue codes.
Legal or compliance review: Search for conceptually similar clauses while capturing precise statute references.
Product search: Surface items using descriptions and exact product IDs.
Internal documentation: Match user queries with acronyms and technical terms that embeddings alone might miss.
Why This Matters for Real Use Cases
Hybrid Search isn’t just a technical improvement—it’s a practical one. Here’s why:
Support teams can search using both error codes and natural language questions.
Legal teams can find exact clauses and related context in policy documents.
Product teams can locate features by keyword or thematic match.
Engineers can query internal docs using exact error strings and broader troubleshooting terms.
Closing Thoughts
Hybrid Search goes beyond a single feature—it reflects an evolving philosophy in AI system design: that language understanding and symbolic precision aren’t mutually exclusive. MindsDB has built this duality into its architecture in a way that’s accessible, tunable, and grounded in SQL—no need to wire up external vector databases or rerankers.
For AI engineers, data teams, and AI practitioners working on real-world LLM applications, this is a powerful addition to the toolbox—especially in domains where the cost of a misretrieved document is high.
You can read more in the official Hybrid Search documentation.
Products
Open Source
© 2026 All rights reserved by MindsDB.

Start conversational analytics with MindsDB
Production-ready infrastructure for agentic analytics
Start conversational analytics with MindsDB
Production-ready infrastructure for agentic analytics

Products
Open Source
© 2026 All rights reserved by MindsDB.

Products
Open Source
© 2026 All rights reserved by MindsDB.
Start conversational analytics with MindsDB
Production-ready infrastructure for agentic analytics