

Building a Knowledge Base with MindsDB
Traditional keyword-based search falls short when users don’t know the exact terms in your data or when they ask questions in natural language. Imagine trying to find “movies about an orphaned boy wizard” when the database only contains the word “magic” – a standard SQL query would miss the connection.
This is where knowledge bases with semantic search shine. By understanding the meaning behind queries rather than just matching keywords, they enable:
Natural language queries: Users can ask questions the way they naturally think (“Show me heartwarming family movies with elements of comedy”) instead of constructing complex keyword searches
Contextual understanding: Finding related content even when exact terms don’t match – searching for “artificial intelligence gone wrong” can surface movies about “rogue robots” or “sentient computers”
Metadata-aware filtering: Combine semantic understanding with structured filters (genre, ratings, dates) for precise, relevant results
This tutorial walks through creating a semantic search knowledge base using MindsDB, an open-source platform that brings machine learning capabilities directly to your data layer. MindsDB simplifies the integration of AI models with databases, making it easy to add semantic search, predictions, and other AI features without complex infrastructure.
We’ll use the IMDB Movies Dataset to learn how to upload data to MindsDB, create a knowledge base with embedding models, and perform both semantic and metadata-filtered searches. By the end, you’ll have a working system that can answer questions like “What movie has a boy defending his home on Christmas?”.
To follow along with the tutorial, download the Jupyter Notebook with the code and materials here for you to reuse.
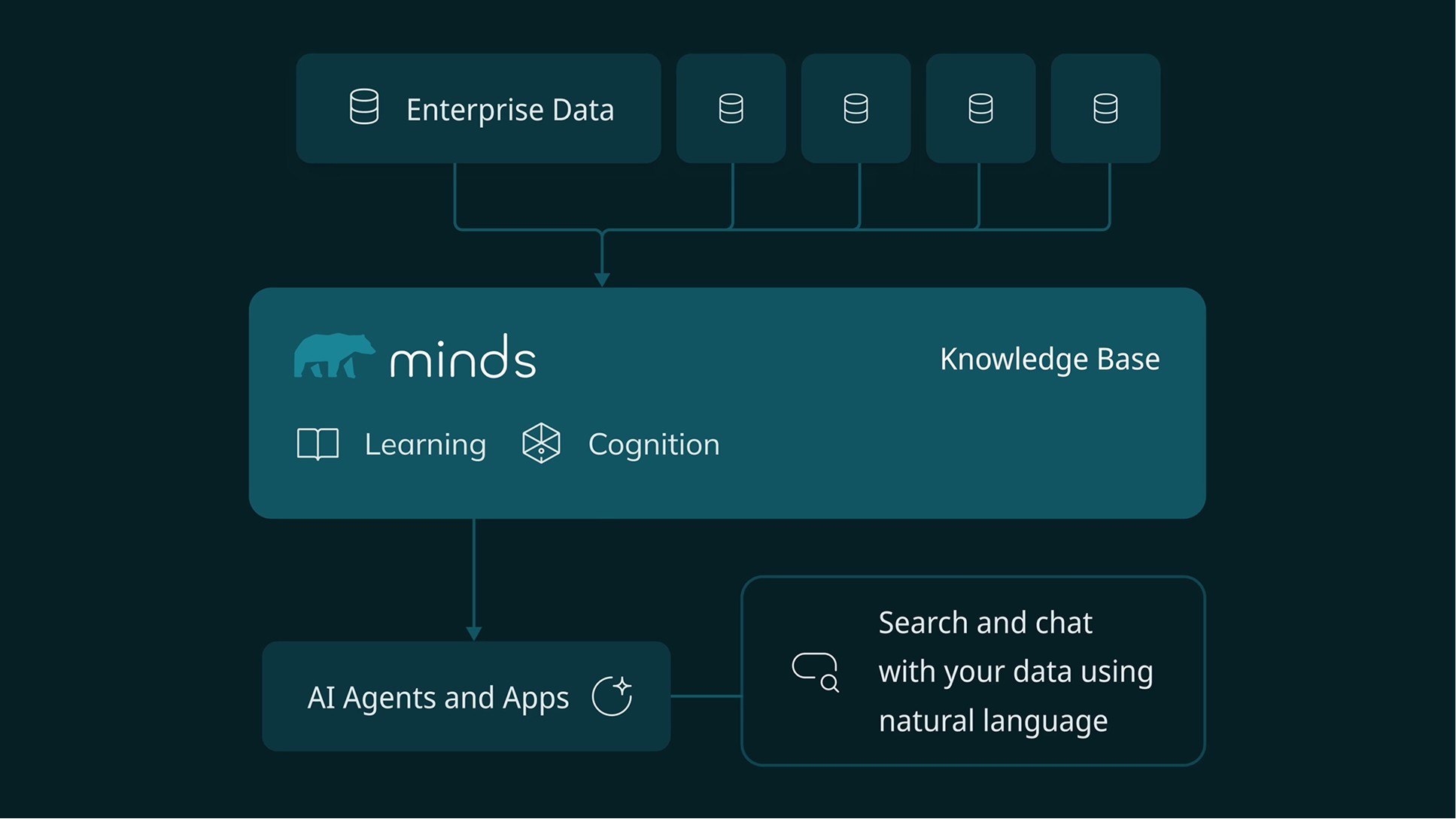
1. Introduction to Knowledge Bases in MindsDB
Knowledge bases in MindsDB provide advanced semantic search capabilities, allowing you to find information based on meaning rather than just keywords. They use embedding models to convert text into vector representations and store them in vector databases for efficient similarity searches.
Let’s begin by setting up our environment and understanding the components of a MindsDB knowledge base.
!pip install mindsdb mindsdb_sdk pandas requests datasets yaspin
!pip install mindsdb mindsdb_sdk pandas requests datasets yaspin
!pip install mindsdb mindsdb_sdk pandas requests datasets yaspin
!pip install mindsdb mindsdb_sdk pandas requests datasets yaspin
Once it is installed you will see this output:
Requirement already satisfied: llvmlite<0.45,>=0.44.0dev0 in /Users/burkov/.pyenv/versions/3.10.6/lib/python3.10/site-packages (from numba->hierarchicalforecast~=0.4.0->mindsdb) (0.44.0) Requirement already satisfied: et-xmlfile in /Users/burkov/.pyenv/versions/3.10.6/lib/python3.10/site-packages (from openpyxl->mindsdb) (2.0.0) Requirement already satisfied: psycopg-binary==3.2.9 in /Users/burkov/.pyenv/versions/3.10.6/lib/python3.10/site-packages (from psycopg[binary]->mindsdb) (3.2.9) Requirement already satisfied: mpmath<1.4,>=1.1.0 in /Users/burkov/.pyenv/versions/3.10.6/lib/python3.10/site-packages (from sympy->onnxruntime>=1.14.1->chromadb~=0.6.3->mindsdb) (1.3.0) [notice] A new release of pip is available: 25.1.1 -> 25.2 [notice] To update, run: pip install --upgrade pip
Requirement already satisfied: llvmlite<0.45,>=0.44.0dev0 in /Users/burkov/.pyenv/versions/3.10.6/lib/python3.10/site-packages (from numba->hierarchicalforecast~=0.4.0->mindsdb) (0.44.0) Requirement already satisfied: et-xmlfile in /Users/burkov/.pyenv/versions/3.10.6/lib/python3.10/site-packages (from openpyxl->mindsdb) (2.0.0) Requirement already satisfied: psycopg-binary==3.2.9 in /Users/burkov/.pyenv/versions/3.10.6/lib/python3.10/site-packages (from psycopg[binary]->mindsdb) (3.2.9) Requirement already satisfied: mpmath<1.4,>=1.1.0 in /Users/burkov/.pyenv/versions/3.10.6/lib/python3.10/site-packages (from sympy->onnxruntime>=1.14.1->chromadb~=0.6.3->mindsdb) (1.3.0) [notice] A new release of pip is available: 25.1.1 -> 25.2 [notice] To update, run: pip install --upgrade pip
Requirement already satisfied: llvmlite<0.45,>=0.44.0dev0 in /Users/burkov/.pyenv/versions/3.10.6/lib/python3.10/site-packages (from numba->hierarchicalforecast~=0.4.0->mindsdb) (0.44.0) Requirement already satisfied: et-xmlfile in /Users/burkov/.pyenv/versions/3.10.6/lib/python3.10/site-packages (from openpyxl->mindsdb) (2.0.0) Requirement already satisfied: psycopg-binary==3.2.9 in /Users/burkov/.pyenv/versions/3.10.6/lib/python3.10/site-packages (from psycopg[binary]->mindsdb) (3.2.9) Requirement already satisfied: mpmath<1.4,>=1.1.0 in /Users/burkov/.pyenv/versions/3.10.6/lib/python3.10/site-packages (from sympy->onnxruntime>=1.14.1->chromadb~=0.6.3->mindsdb) (1.3.0) [notice] A new release of pip is available: 25.1.1 -> 25.2 [notice] To update, run: pip install --upgrade pip
Requirement already satisfied: llvmlite<0.45,>=0.44.0dev0 in /Users/burkov/.pyenv/versions/3.10.6/lib/python3.10/site-packages (from numba->hierarchicalforecast~=0.4.0->mindsdb) (0.44.0) Requirement already satisfied: et-xmlfile in /Users/burkov/.pyenv/versions/3.10.6/lib/python3.10/site-packages (from openpyxl->mindsdb) (2.0.0) Requirement already satisfied: psycopg-binary==3.2.9 in /Users/burkov/.pyenv/versions/3.10.6/lib/python3.10/site-packages (from psycopg[binary]->mindsdb) (3.2.9) Requirement already satisfied: mpmath<1.4,>=1.1.0 in /Users/burkov/.pyenv/versions/3.10.6/lib/python3.10/site-packages (from sympy->onnxruntime>=1.14.1->chromadb~=0.6.3->mindsdb) (1.3.0) [notice] A new release of pip is available: 25.1.1 -> 25.2 [notice] To update, run: pip install --upgrade pip
2. Dataset Selection and Download
We’ll use the IMDB Movies Dataset from Hugging Face (a popular platform for sharing ML datasets and models), which contains movie information from IMDB (the world’s most comprehensive movie and TV database) including descriptions, genres, ratings, and other metadata - perfect for demonstrating both semantic search and metadata filtering.
# Download IMDB Movies Dataset from Hugging Face from datasets import load_dataset import pandas as pd # Load the dataset print("Downloading IMDB Movies dataset...") dataset = load_dataset("jquigl/imdb-genres") df = pd.DataFrame(dataset["train"]) # Preview the dataset print(f"Dataset shape: {df.shape}") df.head()
# Download IMDB Movies Dataset from Hugging Face from datasets import load_dataset import pandas as pd # Load the dataset print("Downloading IMDB Movies dataset...") dataset = load_dataset("jquigl/imdb-genres") df = pd.DataFrame(dataset["train"]) # Preview the dataset print(f"Dataset shape: {df.shape}") df.head()
# Download IMDB Movies Dataset from Hugging Face from datasets import load_dataset import pandas as pd # Load the dataset print("Downloading IMDB Movies dataset...") dataset = load_dataset("jquigl/imdb-genres") df = pd.DataFrame(dataset["train"]) # Preview the dataset print(f"Dataset shape: {df.shape}") df.head()
# Download IMDB Movies Dataset from Hugging Face from datasets import load_dataset import pandas as pd # Load the dataset print("Downloading IMDB Movies dataset...") dataset = load_dataset("jquigl/imdb-genres") df = pd.DataFrame(dataset["train"]) # Preview the dataset print(f"Dataset shape: {df.shape}") df.head()
Upon execution you will receive:
Downloading IMDB Movies dataset... Dataset shape: (238256, 5)
Downloading IMDB Movies dataset... Dataset shape: (238256, 5)
Downloading IMDB Movies dataset... Dataset shape: (238256, 5)
Downloading IMDB Movies dataset... Dataset shape: (238256, 5)
movie title - year | genre | expanded-genres | rating | description | |
|---|---|---|---|---|---|
0 | Flaming Ears - 1992 | Fantasy | Fantasy, Sci-Fi | 6.0 | Flaming Ears is a pop sci-fi lesbian fantasy f... |
1 | Jeg elsker dig - 1957 | Romance | Comedy, Drama, Romance | 5.8 | Six people - three couples - meet at random at... |
2 | Povjerenje - 2021 | Thriller | Thriller | NaN | In a small unnamed town, in year 2025, Krsto w... |
3 | Gulliver Returns - 2021 | Fantasy | Animation, Adventure, Family | 4.4 | The legendary Gulliver returns to the Kingdom ... |
4 | Prithvi Vallabh - 1924 | Biography | Biography, Drama, Romance | NaN | Seminal silent historical film, the story feat... |
As you can see, the dataset contains 238,256 movies with descriptive text spanning multiple decades and genres, though some entries have missing ratings (NaN values) that will need to be addressed during data preparation.
Let’s prepare our dataset for MindsDB by cleaning it up and making sure we have a unique ID column:
# Clean up the data and ensure we have a unique ID # The 'movie title - year' column can serve as a unique identifier df = df.rename(columns={ 'movie title - year': 'movie_id', 'expanded-genres': 'expanded_genres', 'description': 'content' }) # Clean movie IDs to remove problematic characters import re def clean_movie_id(movie_id): if pd.isna(movie_id) or movie_id == '': return "unknown_movie" cleaned = str(movie_id) cleaned = re.sub(r"['\"\!\?\(\)\[\]\/\\*]", "", cleaned) cleaned = cleaned.replace("&", "and").replace(":", "_") cleaned = re.sub(r'\s+', ' ', cleaned).strip() return cleaned if cleaned else "unknown_movie" # Apply the cleaning function to movie_id column df['movie_id'] = df['movie_id'].apply(clean_movie_id) # Remove duplicates based on cleaned movie_id, keeping the first occurrence print(f"Original dataset size: {len(df)}") df = df.drop_duplicates(subset=['movie_id'], keep='first') print(f"After removing duplicates: {len(df)}") # Make sure there are no NaN values df = df.fillna({ 'movie_id': 'unknown_movie', 'genre': 'unknown', 'expanded_genres': '', 'rating': 0.0, 'content': '' }) # Save the prepared dataset df.to_csv('imdb_movies_prepared.csv', index=False) print("Dataset prepared and saved to 'imdb_movies_prepared.csv'") df.head()
# Clean up the data and ensure we have a unique ID # The 'movie title - year' column can serve as a unique identifier df = df.rename(columns={ 'movie title - year': 'movie_id', 'expanded-genres': 'expanded_genres', 'description': 'content' }) # Clean movie IDs to remove problematic characters import re def clean_movie_id(movie_id): if pd.isna(movie_id) or movie_id == '': return "unknown_movie" cleaned = str(movie_id) cleaned = re.sub(r"['\"\!\?\(\)\[\]\/\\*]", "", cleaned) cleaned = cleaned.replace("&", "and").replace(":", "_") cleaned = re.sub(r'\s+', ' ', cleaned).strip() return cleaned if cleaned else "unknown_movie" # Apply the cleaning function to movie_id column df['movie_id'] = df['movie_id'].apply(clean_movie_id) # Remove duplicates based on cleaned movie_id, keeping the first occurrence print(f"Original dataset size: {len(df)}") df = df.drop_duplicates(subset=['movie_id'], keep='first') print(f"After removing duplicates: {len(df)}") # Make sure there are no NaN values df = df.fillna({ 'movie_id': 'unknown_movie', 'genre': 'unknown', 'expanded_genres': '', 'rating': 0.0, 'content': '' }) # Save the prepared dataset df.to_csv('imdb_movies_prepared.csv', index=False) print("Dataset prepared and saved to 'imdb_movies_prepared.csv'") df.head()
# Clean up the data and ensure we have a unique ID # The 'movie title - year' column can serve as a unique identifier df = df.rename(columns={ 'movie title - year': 'movie_id', 'expanded-genres': 'expanded_genres', 'description': 'content' }) # Clean movie IDs to remove problematic characters import re def clean_movie_id(movie_id): if pd.isna(movie_id) or movie_id == '': return "unknown_movie" cleaned = str(movie_id) cleaned = re.sub(r"['\"\!\?\(\)\[\]\/\\*]", "", cleaned) cleaned = cleaned.replace("&", "and").replace(":", "_") cleaned = re.sub(r'\s+', ' ', cleaned).strip() return cleaned if cleaned else "unknown_movie" # Apply the cleaning function to movie_id column df['movie_id'] = df['movie_id'].apply(clean_movie_id) # Remove duplicates based on cleaned movie_id, keeping the first occurrence print(f"Original dataset size: {len(df)}") df = df.drop_duplicates(subset=['movie_id'], keep='first') print(f"After removing duplicates: {len(df)}") # Make sure there are no NaN values df = df.fillna({ 'movie_id': 'unknown_movie', 'genre': 'unknown', 'expanded_genres': '', 'rating': 0.0, 'content': '' }) # Save the prepared dataset df.to_csv('imdb_movies_prepared.csv', index=False) print("Dataset prepared and saved to 'imdb_movies_prepared.csv'") df.head()
# Clean up the data and ensure we have a unique ID # The 'movie title - year' column can serve as a unique identifier df = df.rename(columns={ 'movie title - year': 'movie_id', 'expanded-genres': 'expanded_genres', 'description': 'content' }) # Clean movie IDs to remove problematic characters import re def clean_movie_id(movie_id): if pd.isna(movie_id) or movie_id == '': return "unknown_movie" cleaned = str(movie_id) cleaned = re.sub(r"['\"\!\?\(\)\[\]\/\\*]", "", cleaned) cleaned = cleaned.replace("&", "and").replace(":", "_") cleaned = re.sub(r'\s+', ' ', cleaned).strip() return cleaned if cleaned else "unknown_movie" # Apply the cleaning function to movie_id column df['movie_id'] = df['movie_id'].apply(clean_movie_id) # Remove duplicates based on cleaned movie_id, keeping the first occurrence print(f"Original dataset size: {len(df)}") df = df.drop_duplicates(subset=['movie_id'], keep='first') print(f"After removing duplicates: {len(df)}") # Make sure there are no NaN values df = df.fillna({ 'movie_id': 'unknown_movie', 'genre': 'unknown', 'expanded_genres': '', 'rating': 0.0, 'content': '' }) # Save the prepared dataset df.to_csv('imdb_movies_prepared.csv', index=False) print("Dataset prepared and saved to 'imdb_movies_prepared.csv'") df.head()
You should receive this output once done:
Original dataset size: 238256 After removing duplicates: 161765 Dataset prepared and saved to 'imdb_movies_prepared.csv'
Original dataset size: 238256 After removing duplicates: 161765 Dataset prepared and saved to 'imdb_movies_prepared.csv'
Original dataset size: 238256 After removing duplicates: 161765 Dataset prepared and saved to 'imdb_movies_prepared.csv'
Original dataset size: 238256 After removing duplicates: 161765 Dataset prepared and saved to 'imdb_movies_prepared.csv'
| genre | expanded_genres | rating | content | |
|---|---|---|---|---|---|
0 | Flaming Ears - 1992 | Fantasy | Fantasy, Sci-Fi | 6.0 | Flaming Ears is a pop sci-fi lesbian fantasy f... |
1 | Jeg elsker dig - 1957 | Romance | Comedy, Drama, Romance | 5.8 | Six people - three couples - meet at random at... |
2 | Povjerenje - 2021 | Thriller | Thriller | 0.0 | In a small unnamed town, in year 2025, Krsto w... |
3 | Gulliver Returns - 2021 | Fantasy | Animation, Adventure, Family | 4.4 | The legendary Gulliver returns to the Kingdom ... |
4 | Prithvi Vallabh - 1924 | Biography | Biography, Drama, Romance | 0.0 | Seminal silent historical film, the story feat... |
What we’ve accomplished:
We’ve cleaned and prepared our dataset for MindsDB by standardizing column names, sanitizing movie IDs to remove problematic characters (quotes, special symbols, etc.), and handling missing values. Most importantly, we’ve removed duplicate entries - reducing the dataset from 238,256 to 161,765 unique movies. This deduplication is crucial because knowledge bases require unique identifiers for each entry. The cleaned data is now saved as imdb_movies_prepared.csv with properly formatted movie IDs, filled NaN values (rating defaults to 0.0), and consistent column names ready for upload to MindsDB.
With our dataset cleaned and prepared, we’re ready to connect to MindsDB and upload the data.
3. Uploading the Dataset to MindsDB
Now let’s connect to our local MindsDB instance running in a Docker container and upload the dataset. If you don’t have MindsDB Docker container installed, you should follow this simple official installation tutorial. We’ll first establish a connection to the MindsDB server running on localhost, verify the connection by listing available databases, then upload our prepared CSV file to MindsDB’s built-in files database where it will be accessible for creating the knowledge base.
import mindsdb_sdk # Connect to the MindsDB server # For local Docker installation, use the default URL server = mindsdb_sdk.connect('http://127.0.0.1:47334') print("Connected to MindsDB server") # List available databases to confirm connection databases = server.databases.list() print("Available databases:") for db in databases: print(f"- {db.name}")
import mindsdb_sdk # Connect to the MindsDB server # For local Docker installation, use the default URL server = mindsdb_sdk.connect('http://127.0.0.1:47334') print("Connected to MindsDB server") # List available databases to confirm connection databases = server.databases.list() print("Available databases:") for db in databases: print(f"- {db.name}")
import mindsdb_sdk # Connect to the MindsDB server # For local Docker installation, use the default URL server = mindsdb_sdk.connect('http://127.0.0.1:47334') print("Connected to MindsDB server") # List available databases to confirm connection databases = server.databases.list() print("Available databases:") for db in databases: print(f"- {db.name}")
import mindsdb_sdk # Connect to the MindsDB server # For local Docker installation, use the default URL server = mindsdb_sdk.connect('http://127.0.0.1:47334') print("Connected to MindsDB server") # List available databases to confirm connection databases = server.databases.list() print("Available databases:") for db in databases: print(f"- {db.name}")
In your console you will see:
Connected to MindsDB server Available databases: - files - movies_kb_chromadb
Connected to MindsDB server Available databases: - files - movies_kb_chromadb
Connected to MindsDB server Available databases: - files - movies_kb_chromadb
Connected to MindsDB server Available databases: - files - movies_kb_chromadb
What we’ve accomplished:
We’ve successfully connected to our local MindsDB instance and listed the available databases. Notice the files database - this is a special built-in database in MindsDB specifically designed for uploading and storing datasets (CSV, JSON, Excel files, etc.). We need to use this files database because it acts as a staging area for our data before we can reference it in knowledge base operations.
Now let’s upload our prepared CSV to the files database:
import os, pandas as pd, mindsdb_sdk # connect server = mindsdb_sdk.connect("http://127.0.0.1:47334") # load (or generate) the DataFrame csv_path = os.path.abspath("imdb_movies_prepared.csv") df_movies = pd.read_csv(csv_path) # upload to the built‑in `files` database files_db = server.get_database("files") # <- must be this name table_name = "movies" # delete the whole file‑table if it's there try: files_db.tables.drop(table_name) print(f"dropped {table_name}") except Exception: pass files_db.create_table(table_name, df_movies) print(f"Created table files.{table_name}") print( server.query( f"SELECT movie_id, genre, rating FROM files.{table_name} LIMIT 5" ).fetch() ) print( server.query( f"SELECT count(movie_id) FROM files.{table_name} where rating >= 7.5" ).fetch() )
import os, pandas as pd, mindsdb_sdk # connect server = mindsdb_sdk.connect("http://127.0.0.1:47334") # load (or generate) the DataFrame csv_path = os.path.abspath("imdb_movies_prepared.csv") df_movies = pd.read_csv(csv_path) # upload to the built‑in `files` database files_db = server.get_database("files") # <- must be this name table_name = "movies" # delete the whole file‑table if it's there try: files_db.tables.drop(table_name) print(f"dropped {table_name}") except Exception: pass files_db.create_table(table_name, df_movies) print(f"Created table files.{table_name}") print( server.query( f"SELECT movie_id, genre, rating FROM files.{table_name} LIMIT 5" ).fetch() ) print( server.query( f"SELECT count(movie_id) FROM files.{table_name} where rating >= 7.5" ).fetch() )
import os, pandas as pd, mindsdb_sdk # connect server = mindsdb_sdk.connect("http://127.0.0.1:47334") # load (or generate) the DataFrame csv_path = os.path.abspath("imdb_movies_prepared.csv") df_movies = pd.read_csv(csv_path) # upload to the built‑in `files` database files_db = server.get_database("files") # <- must be this name table_name = "movies" # delete the whole file‑table if it's there try: files_db.tables.drop(table_name) print(f"dropped {table_name}") except Exception: pass files_db.create_table(table_name, df_movies) print(f"Created table files.{table_name}") print( server.query( f"SELECT movie_id, genre, rating FROM files.{table_name} LIMIT 5" ).fetch() ) print( server.query( f"SELECT count(movie_id) FROM files.{table_name} where rating >= 7.5" ).fetch() )
import os, pandas as pd, mindsdb_sdk # connect server = mindsdb_sdk.connect("http://127.0.0.1:47334") # load (or generate) the DataFrame csv_path = os.path.abspath("imdb_movies_prepared.csv") df_movies = pd.read_csv(csv_path) # upload to the built‑in `files` database files_db = server.get_database("files") # <- must be this name table_name = "movies" # delete the whole file‑table if it's there try: files_db.tables.drop(table_name) print(f"dropped {table_name}") except Exception: pass files_db.create_table(table_name, df_movies) print(f"Created table files.{table_name}") print( server.query( f"SELECT movie_id, genre, rating FROM files.{table_name} LIMIT 5" ).fetch() ) print( server.query( f"SELECT count(movie_id) FROM files.{table_name} where rating >= 7.5" ).fetch() )
You will receive this output:
dropped movies Created table files.movies movie_id genre rating 0 Flaming Ears - 1992 Fantasy 6.0 1 Jeg elsker dig - 1957 Romance 5.8 2 Povjerenje - 2021 Thriller 0.0 3 Gulliver Returns - 2021 Fantasy 4.4 4 Prithvi Vallabh - 1924 Biography 0.0 count_0 0 10152
dropped movies Created table files.movies movie_id genre rating 0 Flaming Ears - 1992 Fantasy 6.0 1 Jeg elsker dig - 1957 Romance 5.8 2 Povjerenje - 2021 Thriller 0.0 3 Gulliver Returns - 2021 Fantasy 4.4 4 Prithvi Vallabh - 1924 Biography 0.0 count_0 0 10152
dropped movies Created table files.movies movie_id genre rating 0 Flaming Ears - 1992 Fantasy 6.0 1 Jeg elsker dig - 1957 Romance 5.8 2 Povjerenje - 2021 Thriller 0.0 3 Gulliver Returns - 2021 Fantasy 4.4 4 Prithvi Vallabh - 1924 Biography 0.0 count_0 0 10152
dropped movies Created table files.movies movie_id genre rating 0 Flaming Ears - 1992 Fantasy 6.0 1 Jeg elsker dig - 1957 Romance 5.8 2 Povjerenje - 2021 Thriller 0.0 3 Gulliver Returns - 2021 Fantasy 4.4 4 Prithvi Vallabh - 1924 Biography 0.0 count_0 0 10152
What we’ve accomplished:
We’ve successfully uploaded our prepared dataset to MindsDB’s files database as a table named movies. The code first drops any existing movies table (ensuring a clean slate for re-runs), then creates a new table from our DataFrame. The sample query confirms our data is accessible - we can see the first 5 movies with their genres and ratings. The count query reveals we have 10,152 movies with ratings of 7.5 or higher.
4. Creating a Knowledge Base
Now, let’s create a knowledge base using our IMDB movies data. To enable semantic search, we need to convert our movie descriptions from plain text into numerical vector representations (embeddings) that capture their semantic meaning. This is where embedding models come in - they transform text into high-dimensional vectors where semantically similar content is positioned closer together in vector space. For example, “a boy wizard learning magic” and “young sorcerer at school” would produce similar vectors even though they share no common words.
We’ll use OpenAI’s text-embedding-3-large model for this task. OpenAI’s embedding models are industry-leading in quality, producing vectors that excel at capturing nuanced semantic relationships. They’re also widely supported, well-documented, and integrate seamlessly with MindsDB. While alternatives like open-source models exist, OpenAI offers an excellent balance of performance, reliability, and ease of use for production applications.
The below code assumes the OpenAI API key was set as a envronment variable in tee MindsDB UI settings. Go to the setting to set it up http://localhost:47334/
Alterntively, you can set it up manaually when starting the container: $ docker run –name mindsdb_container -e OPENAI_API_KEY=‘your_key_here’ -p 47334:47334 -p 47335:47335
If you don’t have an OpenAI API key, you should create one by following these steps.
# -- drop the KB if it exists ---------------------------------------------- server.query("DROP KNOWLEDGE_BASE IF EXISTS movies_kb;").fetch() # Knowledge Base creation using mindsdb_sdk try: # This assumes the OpenAI key was set as a envronment variable in tee MindsDB UI settings # Go to the setting to set it up http://localhost:47334/ # Alterntively, you can set it up manaually when starting the container: # $ docker run --name mindsdb_container \ # -e OPENAI_API_KEY='your_key_here' -p 47334:47334 -p 47335:47335 kb_creation_query = server.query(f""" CREATE KNOWLEDGE_BASE movies_kb USING embedding_model = {{ "provider": "openai", "model_name": "text-embedding-3-large" }}, metadata_columns = ['genre', 'expanded_genres', 'rating'], content_columns = ['content'], id_column = 'movie_id'; """) kb_creation_query.fetch() print("Created knowledge base 'movies_kb'") except Exception as e: print(f"Knowledge base creation error or already exists: {e}")
# -- drop the KB if it exists ---------------------------------------------- server.query("DROP KNOWLEDGE_BASE IF EXISTS movies_kb;").fetch() # Knowledge Base creation using mindsdb_sdk try: # This assumes the OpenAI key was set as a envronment variable in tee MindsDB UI settings # Go to the setting to set it up http://localhost:47334/ # Alterntively, you can set it up manaually when starting the container: # $ docker run --name mindsdb_container \ # -e OPENAI_API_KEY='your_key_here' -p 47334:47334 -p 47335:47335 kb_creation_query = server.query(f""" CREATE KNOWLEDGE_BASE movies_kb USING embedding_model = {{ "provider": "openai", "model_name": "text-embedding-3-large" }}, metadata_columns = ['genre', 'expanded_genres', 'rating'], content_columns = ['content'], id_column = 'movie_id'; """) kb_creation_query.fetch() print("Created knowledge base 'movies_kb'") except Exception as e: print(f"Knowledge base creation error or already exists: {e}")
# -- drop the KB if it exists ---------------------------------------------- server.query("DROP KNOWLEDGE_BASE IF EXISTS movies_kb;").fetch() # Knowledge Base creation using mindsdb_sdk try: # This assumes the OpenAI key was set as a envronment variable in tee MindsDB UI settings # Go to the setting to set it up http://localhost:47334/ # Alterntively, you can set it up manaually when starting the container: # $ docker run --name mindsdb_container \ # -e OPENAI_API_KEY='your_key_here' -p 47334:47334 -p 47335:47335 kb_creation_query = server.query(f""" CREATE KNOWLEDGE_BASE movies_kb USING embedding_model = {{ "provider": "openai", "model_name": "text-embedding-3-large" }}, metadata_columns = ['genre', 'expanded_genres', 'rating'], content_columns = ['content'], id_column = 'movie_id'; """) kb_creation_query.fetch() print("Created knowledge base 'movies_kb'") except Exception as e: print(f"Knowledge base creation error or already exists: {e}")
# -- drop the KB if it exists ---------------------------------------------- server.query("DROP KNOWLEDGE_BASE IF EXISTS movies_kb;").fetch() # Knowledge Base creation using mindsdb_sdk try: # This assumes the OpenAI key was set as a envronment variable in tee MindsDB UI settings # Go to the setting to set it up http://localhost:47334/ # Alterntively, you can set it up manaually when starting the container: # $ docker run --name mindsdb_container \ # -e OPENAI_API_KEY='your_key_here' -p 47334:47334 -p 47335:47335 kb_creation_query = server.query(f""" CREATE KNOWLEDGE_BASE movies_kb USING embedding_model = {{ "provider": "openai", "model_name": "text-embedding-3-large" }}, metadata_columns = ['genre', 'expanded_genres', 'rating'], content_columns = ['content'], id_column = 'movie_id'; """) kb_creation_query.fetch() print("Created knowledge base 'movies_kb'") except Exception as e: print(f"Knowledge base creation error or already exists: {e}")
You should receive the output:
Created knowledge base 'movies_kb'
Created knowledge base 'movies_kb'
Created knowledge base 'movies_kb'
Created knowledge base 'movies_kb'
Now let’s insert our movie data into this knowledge base:
from yaspin import yaspin try: with yaspin(text="Inserting data into knowledge base..."): insert_query = server.query(""" INSERT INTO movies_kb SELECT movie_id, genre, expanded_genres, rating, content FROM files.movies WHERE rating >= 7.5 USING track_column = movie_id """).fetch() print("✅ Data inserted successfully!") except Exception as e: print(f"❌ Insert error: {e}")
from yaspin import yaspin try: with yaspin(text="Inserting data into knowledge base..."): insert_query = server.query(""" INSERT INTO movies_kb SELECT movie_id, genre, expanded_genres, rating, content FROM files.movies WHERE rating >= 7.5 USING track_column = movie_id """).fetch() print("✅ Data inserted successfully!") except Exception as e: print(f"❌ Insert error: {e}")
from yaspin import yaspin try: with yaspin(text="Inserting data into knowledge base..."): insert_query = server.query(""" INSERT INTO movies_kb SELECT movie_id, genre, expanded_genres, rating, content FROM files.movies WHERE rating >= 7.5 USING track_column = movie_id """).fetch() print("✅ Data inserted successfully!") except Exception as e: print(f"❌ Insert error: {e}")
from yaspin import yaspin try: with yaspin(text="Inserting data into knowledge base..."): insert_query = server.query(""" INSERT INTO movies_kb SELECT movie_id, genre, expanded_genres, rating, content FROM files.movies WHERE rating >= 7.5 USING track_column = movie_id """).fetch() print("✅ Data inserted successfully!") except Exception as e: print(f"❌ Insert error: {e}")
You should receive the output:
✅ Data inserted successfully
✅ Data inserted successfully
✅ Data inserted successfully
✅ Data inserted successfully
What’s happening here:
This is where the magic happens - we’re inserting data into our knowledge base, and MindsDB is automatically generating embeddings for each movie’s content using the OpenAI model we specified earlier. We’re filtering for movies with ratings of 7.5 or higher to focus on high-quality films. The track_column = movie_id parameter tells MindsDB to use the movie_id as the unique identifier for tracking and updating entries.
This operation may take a few minutes since it’s making API calls to OpenAI to generate embeddings for thousands of movie descriptions.
We verify the upload by counting the entries in our knowledge base:
row_count_df = server.query(""" SELECT COUNT(*) AS cnt FROM (SELECT id FROM movies_kb) AS t; """).fetch() row_count = int(row_count_df.at[0, 'cnt']) print(f"✅ movies_kb now contains {row_count:,} rows.")
row_count_df = server.query(""" SELECT COUNT(*) AS cnt FROM (SELECT id FROM movies_kb) AS t; """).fetch() row_count = int(row_count_df.at[0, 'cnt']) print(f"✅ movies_kb now contains {row_count:,} rows.")
row_count_df = server.query(""" SELECT COUNT(*) AS cnt FROM (SELECT id FROM movies_kb) AS t; """).fetch() row_count = int(row_count_df.at[0, 'cnt']) print(f"✅ movies_kb now contains {row_count:,} rows.")
row_count_df = server.query(""" SELECT COUNT(*) AS cnt FROM (SELECT id FROM movies_kb) AS t; """).fetch() row_count = int(row_count_df.at[0, 'cnt']) print(f"✅ movies_kb now contains {row_count:,} rows.")
Your output should be:
✅ movies_kb now contains 10,152 rows
✅ movies_kb now contains 10,152 rows
✅ movies_kb now contains 10,152 rows
✅ movies_kb now contains 10,152 rows
The 10,152 rows confirm that all highly-rated movies (rating ≥ 7.5) have been successfully embedded and stored. Our knowledge base is now ready for semantic search queries!
Let’s see some data in the knowledge base:
search_query = server.query("SELECT * FROM movies_kb where content='Christmas' order by relevance desc") display(search_query.fetch())
search_query = server.query("SELECT * FROM movies_kb where content='Christmas' order by relevance desc") display(search_query.fetch())
search_query = server.query("SELECT * FROM movies_kb where content='Christmas' order by relevance desc") display(search_query.fetch())
search_query = server.query("SELECT * FROM movies_kb where content='Christmas' order by relevance desc") display(search_query.fetch())
| chunk_id | chunk_content | metadata | distance | relevance | |
|---|---|---|---|---|---|---|
0 | Pixi Post and the Gift Bringers - 2016 | Pixi Post and the Gift Bringers - 2016:content... | Christmas is on danger. Only Pixi Post can sav... | {"_chunk_index": 0, "_content_column": "conten... | 0.598186 | 0.625709 |
1 | Jingle Vingle the Movie - 2022 | Jingle Vingle the Movie - 2022:content:1of1:0t... | Presenting India's First Christmas Themed Movi... | {"_chunk_index": 0, "_content_column": "conten... | 0.609807 | 0.621192 |
2 | For Unto Us - 2021 | For Unto Us - 2021:content:1of1:0to96 | A musical portrayal of the nativity of Jesus C... | {"_chunk_index": 0, "_content_column": "conten... | 0.643808 | 0.608344 |
3 | Joyeux Noel - 2005 | Joyeux Noel - 2005:content:1of1:0to174 | In December 1914, an unofficial Christmas truc... | {"_chunk_index": 0, "_content_column": "conten... | 0.657826 | 0.603200 |
4 | Christmas Snow Angels - 2011 | Christmas Snow Angels - 2011:content:1of1:0to160 | A young girl is dealing with the death of a lo... | {"_chunk_index": 0, "_content_column": "conten... | 0.663354 | 0.601195 |
5 | Save Christmas - 2022 | Save Christmas - 2022:content:1of1:0to138 | Grumpy Dad dislikes Christmas while mum and ki... | {"_chunk_index": 0, "_content_column": "conten... | 0.665107 | 0.600562 |
6 | Beanie - 2022 | Beanie - 2022:content:1of1:0to230 | A boy who has nothing and a girl who seems to ... | {"_chunk_index": 0, "_content_column": "conten... | 0.666201 | 0.600168 |
7 | Carol of the Bells - 2022 | Carol of the Bells - 2022:content:1of1:0to223 | Immortalised as one of the most scintillating ... | {"_chunk_index": 0, "_content_column": "conten... | 0.667653 | 0.599645 |
8 | Winter Thaw - 2016 | Winter Thaw - 2016:content:1of1:0to103 | An old man comes to realize the mistakes he ha... | {"_chunk_index": 0, "_content_column": "conten... | 0.668738 | 0.599255 |
9 | Tis the Season - 1994 | Tis the Season - 1994:content:1of1:0to208 | A little girl, Heather, learns the real meanin... | {"_chunk_index": 0, "_content_column": "conten... | 0.669196 | 0.599091 |
Let’s see what’s inside a metadata column’s cell:
# Query to get full metadata content metadata_query = server.query(""" SELECT id, metadata FROM movies_kb WHERE content='Christmas' ORDER BY relevance DESC LIMIT 5 """).fetch() # Display full metadata without truncation import pandas as pd pd.set_option('display.max_colwidth', None) display(metadata_query) # Or print metadata for each row to see the complete JSON structure print("\nDetailed metadata for top results:") for idx, row in metadata_query.iterrows(): print(f"\n{row['id']}:") print(row['metadata'])
# Query to get full metadata content metadata_query = server.query(""" SELECT id, metadata FROM movies_kb WHERE content='Christmas' ORDER BY relevance DESC LIMIT 5 """).fetch() # Display full metadata without truncation import pandas as pd pd.set_option('display.max_colwidth', None) display(metadata_query) # Or print metadata for each row to see the complete JSON structure print("\nDetailed metadata for top results:") for idx, row in metadata_query.iterrows(): print(f"\n{row['id']}:") print(row['metadata'])
# Query to get full metadata content metadata_query = server.query(""" SELECT id, metadata FROM movies_kb WHERE content='Christmas' ORDER BY relevance DESC LIMIT 5 """).fetch() # Display full metadata without truncation import pandas as pd pd.set_option('display.max_colwidth', None) display(metadata_query) # Or print metadata for each row to see the complete JSON structure print("\nDetailed metadata for top results:") for idx, row in metadata_query.iterrows(): print(f"\n{row['id']}:") print(row['metadata'])
# Query to get full metadata content metadata_query = server.query(""" SELECT id, metadata FROM movies_kb WHERE content='Christmas' ORDER BY relevance DESC LIMIT 5 """).fetch() # Display full metadata without truncation import pandas as pd pd.set_option('display.max_colwidth', None) display(metadata_query) # Or print metadata for each row to see the complete JSON structure print("\nDetailed metadata for top results:") for idx, row in metadata_query.iterrows(): print(f"\n{row['id']}:") print(row['metadata'])
| metadata | |
|---|---|---|
0 | Pixi Post and the Gift Bringers - 2016 | {"_chunk_index": 0, "_content_column": "content", "_end_char": 51, "_original_doc_id": "Pixi Post and the Gift Bringers - 2016", "_original_row_index": "3912", "_source": "TextChunkingPreprocessor", "_start_char": 0, "_updated_at": "2025-10-14 18:17:11", "expanded_genres": "Animation, Adventure, Fantasy", "genre": "Fantasy", "rating": 7.9} |
1 | Jingle Vingle the Movie - 2022 | {"_chunk_index": 0, "_content_column": "content", "_end_char": 161, "_original_doc_id": "Jingle Vingle the Movie - 2022", "_original_row_index": "9700", "_source": "TextChunkingPreprocessor", "_start_char": 0, "_updated_at": "2025-10-14 18:17:11", "expanded_genres": "Family", "genre": "Family", "rating": 9.7} |
2 | For Unto Us - 2021 | {"_chunk_index": 0, "_content_column": "content", "_end_char": 96, "_original_doc_id": "For Unto Us - 2021", "_original_row_index": "4370", "_source": "TextChunkingPreprocessor", "_start_char": 0, "_updated_at": "2025-10-14 18:17:11", "expanded_genres": "Family", "genre": "Family", "rating": 9.1} |
3 | Joyeux Noel - 2005 | {"_chunk_index": 0, "_content_column": "content", "_end_char": 174, "_original_doc_id": "Joyeux Noel - 2005", "_original_row_index": "5021", "_source": "TextChunkingPreprocessor", "_start_char": 0, "_updated_at": "2025-10-14 18:17:11", "expanded_genres": "Drama, History, Music", "genre": "Romance", "rating": 7.7} |
4 | Christmas Snow Angels - 2011 | {"_chunk_index": 0, "_content_column": "content", "_end_char": 160, "_original_doc_id": "Christmas Snow Angels - 2011", "_original_row_index": "4510", "_source": "TextChunkingPreprocessor", "_start_char": 0, "_updated_at": "2025-10-14 18:17:11", "expanded_genres": "Family", "genre": "Family", "rating": 8.5} |
You will receive the output:
Detailed metadata for top results: Pixi Post and the Gift Bringers - 2016: {"_chunk_index": 0, "_content_column": "content", "_end_char": 51, "_original_doc_id": "Pixi Post and the Gift Bringers - 2016", "_original_row_index": "3912", "_source": "TextChunkingPreprocessor", "_start_char": 0, "_updated_at": "2025-10-14 18:17:11", "expanded_genres": "Animation, Adventure, Fantasy", "genre": "Fantasy", "rating": 7.9} Jingle Vingle the Movie - 2022: {"_chunk_index": 0, "_content_column": "content", "_end_char": 161, "_original_doc_id": "Jingle Vingle the Movie - 2022", "_original_row_index": "9700", "_source": "TextChunkingPreprocessor", "_start_char": 0, "_updated_at": "2025-10-14 18:17:11", "expanded_genres": "Family", "genre": "Family", "rating": 9.7} For Unto Us - 2021: {"_chunk_index": 0, "_content_column": "content", "_end_char": 96, "_original_doc_id": "For Unto Us - 2021", "_original_row_index": "4370", "_source": "TextChunkingPreprocessor", "_start_char": 0, "_updated_at": "2025-10-14 18:17:11", "expanded_genres": "Family", "genre": "Family", "rating": 9.1} Joyeux Noel - 2005: {"_chunk_index": 0, "_content_column": "content", "_end_char": 174, "_original_doc_id": "Joyeux Noel - 2005", "_original_row_index": "5021", "_source": "TextChunkingPreprocessor", "_start_char": 0, "_updated_at": "2025-10-14 18:17:11", "expanded_genres": "Drama, History, Music", "genre": "Romance", "rating": 7.7} Christmas Snow Angels - 2011: {"_chunk_index": 0, "_content_column": "content", "_end_char": 160, "_original_doc_id": "C
Detailed metadata for top results: Pixi Post and the Gift Bringers - 2016: {"_chunk_index": 0, "_content_column": "content", "_end_char": 51, "_original_doc_id": "Pixi Post and the Gift Bringers - 2016", "_original_row_index": "3912", "_source": "TextChunkingPreprocessor", "_start_char": 0, "_updated_at": "2025-10-14 18:17:11", "expanded_genres": "Animation, Adventure, Fantasy", "genre": "Fantasy", "rating": 7.9} Jingle Vingle the Movie - 2022: {"_chunk_index": 0, "_content_column": "content", "_end_char": 161, "_original_doc_id": "Jingle Vingle the Movie - 2022", "_original_row_index": "9700", "_source": "TextChunkingPreprocessor", "_start_char": 0, "_updated_at": "2025-10-14 18:17:11", "expanded_genres": "Family", "genre": "Family", "rating": 9.7} For Unto Us - 2021: {"_chunk_index": 0, "_content_column": "content", "_end_char": 96, "_original_doc_id": "For Unto Us - 2021", "_original_row_index": "4370", "_source": "TextChunkingPreprocessor", "_start_char": 0, "_updated_at": "2025-10-14 18:17:11", "expanded_genres": "Family", "genre": "Family", "rating": 9.1} Joyeux Noel - 2005: {"_chunk_index": 0, "_content_column": "content", "_end_char": 174, "_original_doc_id": "Joyeux Noel - 2005", "_original_row_index": "5021", "_source": "TextChunkingPreprocessor", "_start_char": 0, "_updated_at": "2025-10-14 18:17:11", "expanded_genres": "Drama, History, Music", "genre": "Romance", "rating": 7.7} Christmas Snow Angels - 2011: {"_chunk_index": 0, "_content_column": "content", "_end_char": 160, "_original_doc_id": "C
Detailed metadata for top results: Pixi Post and the Gift Bringers - 2016: {"_chunk_index": 0, "_content_column": "content", "_end_char": 51, "_original_doc_id": "Pixi Post and the Gift Bringers - 2016", "_original_row_index": "3912", "_source": "TextChunkingPreprocessor", "_start_char": 0, "_updated_at": "2025-10-14 18:17:11", "expanded_genres": "Animation, Adventure, Fantasy", "genre": "Fantasy", "rating": 7.9} Jingle Vingle the Movie - 2022: {"_chunk_index": 0, "_content_column": "content", "_end_char": 161, "_original_doc_id": "Jingle Vingle the Movie - 2022", "_original_row_index": "9700", "_source": "TextChunkingPreprocessor", "_start_char": 0, "_updated_at": "2025-10-14 18:17:11", "expanded_genres": "Family", "genre": "Family", "rating": 9.7} For Unto Us - 2021: {"_chunk_index": 0, "_content_column": "content", "_end_char": 96, "_original_doc_id": "For Unto Us - 2021", "_original_row_index": "4370", "_source": "TextChunkingPreprocessor", "_start_char": 0, "_updated_at": "2025-10-14 18:17:11", "expanded_genres": "Family", "genre": "Family", "rating": 9.1} Joyeux Noel - 2005: {"_chunk_index": 0, "_content_column": "content", "_end_char": 174, "_original_doc_id": "Joyeux Noel - 2005", "_original_row_index": "5021", "_source": "TextChunkingPreprocessor", "_start_char": 0, "_updated_at": "2025-10-14 18:17:11", "expanded_genres": "Drama, History, Music", "genre": "Romance", "rating": 7.7} Christmas Snow Angels - 2011: {"_chunk_index": 0, "_content_column": "content", "_end_char": 160, "_original_doc_id": "C
Detailed metadata for top results: Pixi Post and the Gift Bringers - 2016: {"_chunk_index": 0, "_content_column": "content", "_end_char": 51, "_original_doc_id": "Pixi Post and the Gift Bringers - 2016", "_original_row_index": "3912", "_source": "TextChunkingPreprocessor", "_start_char": 0, "_updated_at": "2025-10-14 18:17:11", "expanded_genres": "Animation, Adventure, Fantasy", "genre": "Fantasy", "rating": 7.9} Jingle Vingle the Movie - 2022: {"_chunk_index": 0, "_content_column": "content", "_end_char": 161, "_original_doc_id": "Jingle Vingle the Movie - 2022", "_original_row_index": "9700", "_source": "TextChunkingPreprocessor", "_start_char": 0, "_updated_at": "2025-10-14 18:17:11", "expanded_genres": "Family", "genre": "Family", "rating": 9.7} For Unto Us - 2021: {"_chunk_index": 0, "_content_column": "content", "_end_char": 96, "_original_doc_id": "For Unto Us - 2021", "_original_row_index": "4370", "_source": "TextChunkingPreprocessor", "_start_char": 0, "_updated_at": "2025-10-14 18:17:11", "expanded_genres": "Family", "genre": "Family", "rating": 9.1} Joyeux Noel - 2005: {"_chunk_index": 0, "_content_column": "content", "_end_char": 174, "_original_doc_id": "Joyeux Noel - 2005", "_original_row_index": "5021", "_source": "TextChunkingPreprocessor", "_start_char": 0, "_updated_at": "2025-10-14 18:17:11", "expanded_genres": "Drama, History, Music", "genre": "Romance", "rating": 7.7} Christmas Snow Angels - 2011: {"_chunk_index": 0, "_content_column": "content", "_end_char": 160, "_original_doc_id": "C
Understanding the metadata structure:
A chunk is a segment of text created when MindsDB breaks down longer content into smaller, searchable pieces to fit within the embedding model’s input limits. This chunking ensures searches can pinpoint specific passages within larger documents rather than only matching entire documents.
The metadata field contains two types of information:
System-generated fields (prefixed with underscores) that MindsDB automatically adds:
_chunk_index: The sequential position of this chunk (0 means it’s the first/only chunk)_content_column: Which source column contained the text (“content” in our case)_start_charand_end_char: Character positions showing where this chunk begins and ends in the original text (0 to 51 means a 51-character description)_original_doc_id: The complete document identifier with content column appended_original_row_index: The row number from the original dataset (row 3912)_source: The preprocessor used for chunking (“TextChunkingPreprocessor”)_updated_at: Timestamp of when this entry was inserted or updated
User-defined metadata columns that we specified during knowledge base creation:
genre: “Fantasy” - the primary genre we defined as metadataexpanded_genres: “Animation, Adventure, Fantasy” - the full genre listrating: 7.9 - the movie’s IMDB rating
This combined metadata enables powerful hybrid search - you can perform semantic searches on content while filtering by structured metadata fields like genre or rating thresholds. For example, you could search for “Christmas adventure stories” and filter only for Animation genre with ratings above 7.5.
5. Performing Semantic Searches with RAG
Now that our knowledge base is populated and indexed, let’s implement a complete Retrieval-Augmented Generation (RAG) workflow. RAG combines semantic search with large language models to answer questions based on your specific data - in our case, movie descriptions.
What is RAG?
RAG is a technique that enhances LLM responses by grounding them in retrieved, relevant documents from your knowledge base. Instead of relying solely on the model’s training data, RAG retrieves the most relevant chunks from your knowledge base and uses them as context for generating answers. This ensures responses are factually accurate and based on your actual data.
The RAG workflow:
import openai from IPython.display import display client = openai.OpenAI(api_key=openai_api_key) def answer_question_with_llm(question: str): # 1. Use the existing search_kb function to get the most relevant chunks. print(f"Searching knowledge base for: '{question}'\n") relevant_chunks_df = search_kb(question, limit=100) print("Found the following relevant chunks:") display(relevant_chunks_df[['id', 'chunk_content', 'relevance']]) # 2. Concatenate the 'chunk_content' to form a single context string. context = "\n---\n".join(relevant_chunks_df['chunk_content']) # 3. Create the prompt for the gpt-4o model. prompt = f""" You are a movie expert assistant. Based *only* on the following movie summaries (context), answer the user's question. If the context doesn't contain the answer, state that you cannot answer based on the provided information. CONTEXT: {context} QUESTION: {question} """ # 4. Call the OpenAI API to get the answer. print("\nSending request to GPT-4o to generate a definitive answer...") try: response = client.chat.completions.create( model="gpt-4o", messages=[ {"role": "system", "content": "You are a helpful assistant that answers questions about movies using only the provided context."}, {"role": "user", "content": prompt} ], temperature=0.0 # We want a factual answer based on the text ) answer = response.choices[0].message.content return answer except Exception as e: return f"An error occurred while calling the OpenAI API: {e}" user_question = "Who a boy must defend his home against on Christmas eve?" final_answer = answer_question_with_llm(user_question) print("\n--- Generated Answer ---") print(final_answer)
import openai from IPython.display import display client = openai.OpenAI(api_key=openai_api_key) def answer_question_with_llm(question: str): # 1. Use the existing search_kb function to get the most relevant chunks. print(f"Searching knowledge base for: '{question}'\n") relevant_chunks_df = search_kb(question, limit=100) print("Found the following relevant chunks:") display(relevant_chunks_df[['id', 'chunk_content', 'relevance']]) # 2. Concatenate the 'chunk_content' to form a single context string. context = "\n---\n".join(relevant_chunks_df['chunk_content']) # 3. Create the prompt for the gpt-4o model. prompt = f""" You are a movie expert assistant. Based *only* on the following movie summaries (context), answer the user's question. If the context doesn't contain the answer, state that you cannot answer based on the provided information. CONTEXT: {context} QUESTION: {question} """ # 4. Call the OpenAI API to get the answer. print("\nSending request to GPT-4o to generate a definitive answer...") try: response = client.chat.completions.create( model="gpt-4o", messages=[ {"role": "system", "content": "You are a helpful assistant that answers questions about movies using only the provided context."}, {"role": "user", "content": prompt} ], temperature=0.0 # We want a factual answer based on the text ) answer = response.choices[0].message.content return answer except Exception as e: return f"An error occurred while calling the OpenAI API: {e}" user_question = "Who a boy must defend his home against on Christmas eve?" final_answer = answer_question_with_llm(user_question) print("\n--- Generated Answer ---") print(final_answer)
import openai from IPython.display import display client = openai.OpenAI(api_key=openai_api_key) def answer_question_with_llm(question: str): # 1. Use the existing search_kb function to get the most relevant chunks. print(f"Searching knowledge base for: '{question}'\n") relevant_chunks_df = search_kb(question, limit=100) print("Found the following relevant chunks:") display(relevant_chunks_df[['id', 'chunk_content', 'relevance']]) # 2. Concatenate the 'chunk_content' to form a single context string. context = "\n---\n".join(relevant_chunks_df['chunk_content']) # 3. Create the prompt for the gpt-4o model. prompt = f""" You are a movie expert assistant. Based *only* on the following movie summaries (context), answer the user's question. If the context doesn't contain the answer, state that you cannot answer based on the provided information. CONTEXT: {context} QUESTION: {question} """ # 4. Call the OpenAI API to get the answer. print("\nSending request to GPT-4o to generate a definitive answer...") try: response = client.chat.completions.create( model="gpt-4o", messages=[ {"role": "system", "content": "You are a helpful assistant that answers questions about movies using only the provided context."}, {"role": "user", "content": prompt} ], temperature=0.0 # We want a factual answer based on the text ) answer = response.choices[0].message.content return answer except Exception as e: return f"An error occurred while calling the OpenAI API: {e}" user_question = "Who a boy must defend his home against on Christmas eve?" final_answer = answer_question_with_llm(user_question) print("\n--- Generated Answer ---") print(final_answer)
import openai from IPython.display import display client = openai.OpenAI(api_key=openai_api_key) def answer_question_with_llm(question: str): # 1. Use the existing search_kb function to get the most relevant chunks. print(f"Searching knowledge base for: '{question}'\n") relevant_chunks_df = search_kb(question, limit=100) print("Found the following relevant chunks:") display(relevant_chunks_df[['id', 'chunk_content', 'relevance']]) # 2. Concatenate the 'chunk_content' to form a single context string. context = "\n---\n".join(relevant_chunks_df['chunk_content']) # 3. Create the prompt for the gpt-4o model. prompt = f""" You are a movie expert assistant. Based *only* on the following movie summaries (context), answer the user's question. If the context doesn't contain the answer, state that you cannot answer based on the provided information. CONTEXT: {context} QUESTION: {question} """ # 4. Call the OpenAI API to get the answer. print("\nSending request to GPT-4o to generate a definitive answer...") try: response = client.chat.completions.create( model="gpt-4o", messages=[ {"role": "system", "content": "You are a helpful assistant that answers questions about movies using only the provided context."}, {"role": "user", "content": prompt} ], temperature=0.0 # We want a factual answer based on the text ) answer = response.choices[0].message.content return answer except Exception as e: return f"An error occurred while calling the OpenAI API: {e}" user_question = "Who a boy must defend his home against on Christmas eve?" final_answer = answer_question_with_llm(user_question) print("\n--- Generated Answer ---") print(final_answer)
You should receive the following output:
Searching knowledge base for: 'Who a boy must defend his home against on Christmas eve?' SELECT * FROM movies_kb WHERE content = 'Who a boy must defend his home against on Christmas eve?' ORDER BY relevance DESC LIMIT 100; Found the following relevant chunks:
Searching knowledge base for: 'Who a boy must defend his home against on Christmas eve?' SELECT * FROM movies_kb WHERE content = 'Who a boy must defend his home against on Christmas eve?' ORDER BY relevance DESC LIMIT 100; Found the following relevant chunks:
Searching knowledge base for: 'Who a boy must defend his home against on Christmas eve?' SELECT * FROM movies_kb WHERE content = 'Who a boy must defend his home against on Christmas eve?' ORDER BY relevance DESC LIMIT 100; Found the following relevant chunks:
Searching knowledge base for: 'Who a boy must defend his home against on Christmas eve?' SELECT * FROM movies_kb WHERE content = 'Who a boy must defend his home against on Christmas eve?' ORDER BY relevance DESC LIMIT 100; Found the following relevant chunks:
| chunk_content | relevance | |
|---|---|---|---|
0 | Snap - 2005 | A young boy must defend his house after his pa... | 0.704163 |
1 | Home Alone - 1990 | An eight-year-old troublemaker, mistakenly lef... | 0.687292 |
2 | Save Christmas - 2022 | Grumpy Dad dislikes Christmas while mum and ki... | 0.663474 |
3 | Sinterklaas and Het Pieten Duo_ Het Gestolen S... | This year everything seems to be according to ... | 0.651742 |
4 | Pixi Post and the Gift Bringers - 2016 | Christmas is on danger. Only Pixi Post can sav... | 0.644813 |
... | ... | ... | ... |
95 | Young Citizen Patriots_ Young Kid Ambassadors ... | Young Patriots for good versus evil. | 0.606097 |
96 | Kireedam - 1989 | The life of a young man turns upside down when... | 0.606093 |
97 | Fangs Vs. Spurs - 2016 | When revengeful vampires attack, a group of se... | 0.605888 |
98 | The Iron Giant - 1999 | A young boy befriends a giant robot from outer... | 0.605594 |
99 | Shoplifters - 2018 | A family of small-time crooks take in a child ... | 0.605376 |
100 rows × 3 columns Sending request to GPT-4o to generate a definitive answer... --- Generated Answer --- The boy must defend his home against a pair of burglars on Christmas Eve
100 rows × 3 columns Sending request to GPT-4o to generate a definitive answer... --- Generated Answer --- The boy must defend his home against a pair of burglars on Christmas Eve
100 rows × 3 columns Sending request to GPT-4o to generate a definitive answer... --- Generated Answer --- The boy must defend his home against a pair of burglars on Christmas Eve
100 rows × 3 columns Sending request to GPT-4o to generate a definitive answer... --- Generated Answer --- The boy must defend his home against a pair of burglars on Christmas Eve
What happened here:
This function implements a complete RAG pipeline in four steps:
Semantic Search: The knowledge base is queried with the natural language question. MindsDB’s semantic search retrieves the top 100 most relevant movie chunks, ranked by relevance score. Notice how the search found “Home Alone” (relevance: 0.687) even though our question didn’t mention the movie title - semantic search understood the meaning of “boy defending home on Christmas.”
Context Assembly: All retrieved chunk contents are concatenated into a single context string, separated by dividers. This context now contains relevant information from multiple movies.
Prompt Engineering: We construct a carefully crafted prompt that instructs GPT-4o to act as a movie expert and answer only based on the provided context. This grounding reduces the chance that the model will hallucinate or use information outside our knowledge base.
LLM Generation: The OpenAI API processes the prompt with temperature=0.0 (deterministic, factual responses) and generates an answer by synthesizing information from the retrieved chunks.
The power of RAG:
The final answer - “The boy must defend his home against a pair of burglars on Christmas Eve” - demonstrates RAG’s strength. The LLM successfully:
Identified the most relevant movie (Home Alone) from the semantic search results
Extracted the key information about burglars from the movie description
Synthesized a clear, concise answer grounded in our actual data
This RAG approach ensures answers are (almost) always based on your knowledge base rather than the model’s general training data, making it a great solution for domain-specific applications like customer support, internal documentation systems, or specialized research assistants.
Let’s wrap up this tutorial with one more query:
user_question = "What Anakin was lured into by Chancellor Palpatine?" final_answer = answer_question_with_llm(user_question) print("\n--- Generated Answer ---") print(final_answer)
user_question = "What Anakin was lured into by Chancellor Palpatine?" final_answer = answer_question_with_llm(user_question) print("\n--- Generated Answer ---") print(final_answer)
user_question = "What Anakin was lured into by Chancellor Palpatine?" final_answer = answer_question_with_llm(user_question) print("\n--- Generated Answer ---") print(final_answer)
user_question = "What Anakin was lured into by Chancellor Palpatine?" final_answer = answer_question_with_llm(user_question) print("\n--- Generated Answer ---") print(final_answer)
The output:
Searching knowledge base for: 'What Anakin was lured into by Chancellor Palpatine?' SELECT * FROM movies_kb WHERE content = 'What Anakin was lured into by Chancellor Palpatine?' ORDER BY relevance DESC LIMIT 100; Found the following relevant chunks:
Searching knowledge base for: 'What Anakin was lured into by Chancellor Palpatine?' SELECT * FROM movies_kb WHERE content = 'What Anakin was lured into by Chancellor Palpatine?' ORDER BY relevance DESC LIMIT 100; Found the following relevant chunks:
Searching knowledge base for: 'What Anakin was lured into by Chancellor Palpatine?' SELECT * FROM movies_kb WHERE content = 'What Anakin was lured into by Chancellor Palpatine?' ORDER BY relevance DESC LIMIT 100; Found the following relevant chunks:
Searching knowledge base for: 'What Anakin was lured into by Chancellor Palpatine?' SELECT * FROM movies_kb WHERE content = 'What Anakin was lured into by Chancellor Palpatine?' ORDER BY relevance DESC LIMIT 100; Found the following relevant chunks:
id | chunk_content | relevance | |
|---|---|---|---|
0 | Star Wars_ Episode III - Revenge of the Sith -... | Three years into the Clone Wars, Obi-Wan pursu... | 0.712999 |
1 | Sith Wars_ Episode I - The Return of the Sith ... | Emperor Palpatine reigns the galaxy, along wit... | 0.646388 |
2 | Sith Wars_ Episode II - Legacy of the Sith - 2022 | After the defeat at Agamar, Darth Vader discov... | 0.638359 |
3 | The Last Padawan 2 - 2021 | The Last Padawan is back with The Evil Empire ... | 0.631523 |
4 | Star Wars_ Episode VI - Return of the Jedi - 1983 | After rescuing Han Solo from Jabba the Hutt, t... | 0.625445 |
... | ... | ... | ... |
95 | Serenity - 2005 | The crew of the ship Serenity try to evade an ... | 0.570973 |
96 | Crackula Goes to Hollywood - 2015 | A mysterious man from Alaska, known to be from... | 0.570895 |
97 | Horseface 2_ Reverse the Curse - 2017 | Delshawn, "The Chosen One", is back in action,... | 0.570883 |
98 | Khamsa - The Well of Oblivion - 2022 | Down in a dark well, an amnesiac little boy ca... | 0.570599 |
99 | Ben-Hur - 1959 | After a Jewish prince is betrayed and sent int... | 0.570478 |
100 rows × 3 columns Sending request to GPT-4o to generate a definitive answer... --- Generated Answer --- Anakin was lured by Chancellor Palpatine into a sinister plot to rule the galaxy
100 rows × 3 columns Sending request to GPT-4o to generate a definitive answer... --- Generated Answer --- Anakin was lured by Chancellor Palpatine into a sinister plot to rule the galaxy
100 rows × 3 columns Sending request to GPT-4o to generate a definitive answer... --- Generated Answer --- Anakin was lured by Chancellor Palpatine into a sinister plot to rule the galaxy
100 rows × 3 columns Sending request to GPT-4o to generate a definitive answer... --- Generated Answer --- Anakin was lured by Chancellor Palpatine into a sinister plot to rule the galaxy
Conclusion
Congratulations! You’ve successfully built a semantic search knowledge base with MindsDB that can understand and answer natural language questions about movies. Let’s recap what we’ve accomplished:
What you’ve built:
A knowledge base containing 10,152 high-quality movies with semantic embeddings
A complete RAG (Retrieval-Augmented Generation) pipeline that combines semantic search with LLM-powered question answering
A system that understands meaning, not just keywords - finding “Home Alone” when asked about “a boy defending his home on Christmas” and “Star Wars Episode III” when queried about “Anakin and Chancellor Palpatine”
Key takeaways:
Semantic search transcends keywords: MindsDB’s knowledge bases use embeddings to understand the meaning behind queries, enabling more intuitive and natural search experiences
Hybrid search combines the best of both worlds: By integrating semantic understanding with metadata filtering (genre, ratings, etc.), you can create powerful, precise queries
RAG grounds AI in your data: Instead of relying on potentially outdated or hallucinated information, RAG ensures answers are most of the time (LLMs always hallucinate, but grounding them in your factual data reduces hallucinations to a great extent) based on your actual knowledge base
Where to go from here:
This tutorial demonstrated the fundamentals, but knowledge bases can power much more:
Build chatbots that answer questions about your company’s documentation, policies, or products
Create recommendation systems that understand user preferences semantically
Develop research assistants for academic papers, legal documents, or technical manuals
Scale to production by connecting MindsDB to your existing databases, APIs, or data warehouses
The beauty of MindsDB is that you control it entirely through SQL - a familiar interface that makes advanced AI capabilities accessible without complex infrastructure or learning new APIs or domain-specific programming languages. Whether you’re working with customer support tickets, research papers, code repositories, or movie databases, the same principles apply.
Now it’s your turn to build something amazing with your own data!
You can also check out the full webinar, Fast‑Track Knowledge Bases: How to Build Semantic AI Search.
Building a Knowledge Base with MindsDB
Traditional keyword-based search falls short when users don’t know the exact terms in your data or when they ask questions in natural language. Imagine trying to find “movies about an orphaned boy wizard” when the database only contains the word “magic” – a standard SQL query would miss the connection.
This is where knowledge bases with semantic search shine. By understanding the meaning behind queries rather than just matching keywords, they enable:
Natural language queries: Users can ask questions the way they naturally think (“Show me heartwarming family movies with elements of comedy”) instead of constructing complex keyword searches
Contextual understanding: Finding related content even when exact terms don’t match – searching for “artificial intelligence gone wrong” can surface movies about “rogue robots” or “sentient computers”
Metadata-aware filtering: Combine semantic understanding with structured filters (genre, ratings, dates) for precise, relevant results
This tutorial walks through creating a semantic search knowledge base using MindsDB, an open-source platform that brings machine learning capabilities directly to your data layer. MindsDB simplifies the integration of AI models with databases, making it easy to add semantic search, predictions, and other AI features without complex infrastructure.
We’ll use the IMDB Movies Dataset to learn how to upload data to MindsDB, create a knowledge base with embedding models, and perform both semantic and metadata-filtered searches. By the end, you’ll have a working system that can answer questions like “What movie has a boy defending his home on Christmas?”.
To follow along with the tutorial, download the Jupyter Notebook with the code and materials here for you to reuse.
1. Introduction to Knowledge Bases in MindsDB
Knowledge bases in MindsDB provide advanced semantic search capabilities, allowing you to find information based on meaning rather than just keywords. They use embedding models to convert text into vector representations and store them in vector databases for efficient similarity searches.
Let’s begin by setting up our environment and understanding the components of a MindsDB knowledge base.
!pip install mindsdb mindsdb_sdk pandas requests datasets yaspin
Once it is installed you will see this output:
Requirement already satisfied: llvmlite<0.45,>=0.44.0dev0 in /Users/burkov/.pyenv/versions/3.10.6/lib/python3.10/site-packages (from numba->hierarchicalforecast~=0.4.0->mindsdb) (0.44.0) Requirement already satisfied: et-xmlfile in /Users/burkov/.pyenv/versions/3.10.6/lib/python3.10/site-packages (from openpyxl->mindsdb) (2.0.0) Requirement already satisfied: psycopg-binary==3.2.9 in /Users/burkov/.pyenv/versions/3.10.6/lib/python3.10/site-packages (from psycopg[binary]->mindsdb) (3.2.9) Requirement already satisfied: mpmath<1.4,>=1.1.0 in /Users/burkov/.pyenv/versions/3.10.6/lib/python3.10/site-packages (from sympy->onnxruntime>=1.14.1->chromadb~=0.6.3->mindsdb) (1.3.0) [notice] A new release of pip is available: 25.1.1 -> 25.2 [notice] To update, run: pip install --upgrade pip
2. Dataset Selection and Download
We’ll use the IMDB Movies Dataset from Hugging Face (a popular platform for sharing ML datasets and models), which contains movie information from IMDB (the world’s most comprehensive movie and TV database) including descriptions, genres, ratings, and other metadata - perfect for demonstrating both semantic search and metadata filtering.
# Download IMDB Movies Dataset from Hugging Face from datasets import load_dataset import pandas as pd # Load the dataset print("Downloading IMDB Movies dataset...") dataset = load_dataset("jquigl/imdb-genres") df = pd.DataFrame(dataset["train"]) # Preview the dataset print(f"Dataset shape: {df.shape}") df.head()
Upon execution you will receive:
Downloading IMDB Movies dataset... Dataset shape: (238256, 5)
movie title - year | genre | expanded-genres | rating | description | |
|---|---|---|---|---|---|
0 | Flaming Ears - 1992 | Fantasy | Fantasy, Sci-Fi | 6.0 | Flaming Ears is a pop sci-fi lesbian fantasy f... |
1 | Jeg elsker dig - 1957 | Romance | Comedy, Drama, Romance | 5.8 | Six people - three couples - meet at random at... |
2 | Povjerenje - 2021 | Thriller | Thriller | NaN | In a small unnamed town, in year 2025, Krsto w... |
3 | Gulliver Returns - 2021 | Fantasy | Animation, Adventure, Family | 4.4 | The legendary Gulliver returns to the Kingdom ... |
4 | Prithvi Vallabh - 1924 | Biography | Biography, Drama, Romance | NaN | Seminal silent historical film, the story feat... |
As you can see, the dataset contains 238,256 movies with descriptive text spanning multiple decades and genres, though some entries have missing ratings (NaN values) that will need to be addressed during data preparation.
Let’s prepare our dataset for MindsDB by cleaning it up and making sure we have a unique ID column:
# Clean up the data and ensure we have a unique ID # The 'movie title - year' column can serve as a unique identifier df = df.rename(columns={ 'movie title - year': 'movie_id', 'expanded-genres': 'expanded_genres', 'description': 'content' }) # Clean movie IDs to remove problematic characters import re def clean_movie_id(movie_id): if pd.isna(movie_id) or movie_id == '': return "unknown_movie" cleaned = str(movie_id) cleaned = re.sub(r"['\"\!\?\(\)\[\]\/\\*]", "", cleaned) cleaned = cleaned.replace("&", "and").replace(":", "_") cleaned = re.sub(r'\s+', ' ', cleaned).strip() return cleaned if cleaned else "unknown_movie" # Apply the cleaning function to movie_id column df['movie_id'] = df['movie_id'].apply(clean_movie_id) # Remove duplicates based on cleaned movie_id, keeping the first occurrence print(f"Original dataset size: {len(df)}") df = df.drop_duplicates(subset=['movie_id'], keep='first') print(f"After removing duplicates: {len(df)}") # Make sure there are no NaN values df = df.fillna({ 'movie_id': 'unknown_movie', 'genre': 'unknown', 'expanded_genres': '', 'rating': 0.0, 'content': '' }) # Save the prepared dataset df.to_csv('imdb_movies_prepared.csv', index=False) print("Dataset prepared and saved to 'imdb_movies_prepared.csv'") df.head()
You should receive this output once done:
Original dataset size: 238256 After removing duplicates: 161765 Dataset prepared and saved to 'imdb_movies_prepared.csv'
| genre | expanded_genres | rating | content | |
|---|---|---|---|---|---|
0 | Flaming Ears - 1992 | Fantasy | Fantasy, Sci-Fi | 6.0 | Flaming Ears is a pop sci-fi lesbian fantasy f... |
1 | Jeg elsker dig - 1957 | Romance | Comedy, Drama, Romance | 5.8 | Six people - three couples - meet at random at... |
2 | Povjerenje - 2021 | Thriller | Thriller | 0.0 | In a small unnamed town, in year 2025, Krsto w... |
3 | Gulliver Returns - 2021 | Fantasy | Animation, Adventure, Family | 4.4 | The legendary Gulliver returns to the Kingdom ... |
4 | Prithvi Vallabh - 1924 | Biography | Biography, Drama, Romance | 0.0 | Seminal silent historical film, the story feat... |
What we’ve accomplished:
We’ve cleaned and prepared our dataset for MindsDB by standardizing column names, sanitizing movie IDs to remove problematic characters (quotes, special symbols, etc.), and handling missing values. Most importantly, we’ve removed duplicate entries - reducing the dataset from 238,256 to 161,765 unique movies. This deduplication is crucial because knowledge bases require unique identifiers for each entry. The cleaned data is now saved as imdb_movies_prepared.csv with properly formatted movie IDs, filled NaN values (rating defaults to 0.0), and consistent column names ready for upload to MindsDB.
With our dataset cleaned and prepared, we’re ready to connect to MindsDB and upload the data.
3. Uploading the Dataset to MindsDB
Now let’s connect to our local MindsDB instance running in a Docker container and upload the dataset. If you don’t have MindsDB Docker container installed, you should follow this simple official installation tutorial. We’ll first establish a connection to the MindsDB server running on localhost, verify the connection by listing available databases, then upload our prepared CSV file to MindsDB’s built-in files database where it will be accessible for creating the knowledge base.
import mindsdb_sdk # Connect to the MindsDB server # For local Docker installation, use the default URL server = mindsdb_sdk.connect('http://127.0.0.1:47334') print("Connected to MindsDB server") # List available databases to confirm connection databases = server.databases.list() print("Available databases:") for db in databases: print(f"- {db.name}")
In your console you will see:
Connected to MindsDB server Available databases: - files - movies_kb_chromadb
What we’ve accomplished:
We’ve successfully connected to our local MindsDB instance and listed the available databases. Notice the files database - this is a special built-in database in MindsDB specifically designed for uploading and storing datasets (CSV, JSON, Excel files, etc.). We need to use this files database because it acts as a staging area for our data before we can reference it in knowledge base operations.
Now let’s upload our prepared CSV to the files database:
import os, pandas as pd, mindsdb_sdk # connect server = mindsdb_sdk.connect("http://127.0.0.1:47334") # load (or generate) the DataFrame csv_path = os.path.abspath("imdb_movies_prepared.csv") df_movies = pd.read_csv(csv_path) # upload to the built‑in `files` database files_db = server.get_database("files") # <- must be this name table_name = "movies" # delete the whole file‑table if it's there try: files_db.tables.drop(table_name) print(f"dropped {table_name}") except Exception: pass files_db.create_table(table_name, df_movies) print(f"Created table files.{table_name}") print( server.query( f"SELECT movie_id, genre, rating FROM files.{table_name} LIMIT 5" ).fetch() ) print( server.query( f"SELECT count(movie_id) FROM files.{table_name} where rating >= 7.5" ).fetch() )
You will receive this output:
dropped movies Created table files.movies movie_id genre rating 0 Flaming Ears - 1992 Fantasy 6.0 1 Jeg elsker dig - 1957 Romance 5.8 2 Povjerenje - 2021 Thriller 0.0 3 Gulliver Returns - 2021 Fantasy 4.4 4 Prithvi Vallabh - 1924 Biography 0.0 count_0 0 10152
What we’ve accomplished:
We’ve successfully uploaded our prepared dataset to MindsDB’s files database as a table named movies. The code first drops any existing movies table (ensuring a clean slate for re-runs), then creates a new table from our DataFrame. The sample query confirms our data is accessible - we can see the first 5 movies with their genres and ratings. The count query reveals we have 10,152 movies with ratings of 7.5 or higher.
4. Creating a Knowledge Base
Now, let’s create a knowledge base using our IMDB movies data. To enable semantic search, we need to convert our movie descriptions from plain text into numerical vector representations (embeddings) that capture their semantic meaning. This is where embedding models come in - they transform text into high-dimensional vectors where semantically similar content is positioned closer together in vector space. For example, “a boy wizard learning magic” and “young sorcerer at school” would produce similar vectors even though they share no common words.
We’ll use OpenAI’s text-embedding-3-large model for this task. OpenAI’s embedding models are industry-leading in quality, producing vectors that excel at capturing nuanced semantic relationships. They’re also widely supported, well-documented, and integrate seamlessly with MindsDB. While alternatives like open-source models exist, OpenAI offers an excellent balance of performance, reliability, and ease of use for production applications.
The below code assumes the OpenAI API key was set as a envronment variable in tee MindsDB UI settings. Go to the setting to set it up http://localhost:47334/
Alterntively, you can set it up manaually when starting the container: $ docker run –name mindsdb_container -e OPENAI_API_KEY=‘your_key_here’ -p 47334:47334 -p 47335:47335
If you don’t have an OpenAI API key, you should create one by following these steps.
# -- drop the KB if it exists ---------------------------------------------- server.query("DROP KNOWLEDGE_BASE IF EXISTS movies_kb;").fetch() # Knowledge Base creation using mindsdb_sdk try: # This assumes the OpenAI key was set as a envronment variable in tee MindsDB UI settings # Go to the setting to set it up http://localhost:47334/ # Alterntively, you can set it up manaually when starting the container: # $ docker run --name mindsdb_container \ # -e OPENAI_API_KEY='your_key_here' -p 47334:47334 -p 47335:47335 kb_creation_query = server.query(f""" CREATE KNOWLEDGE_BASE movies_kb USING embedding_model = {{ "provider": "openai", "model_name": "text-embedding-3-large" }}, metadata_columns = ['genre', 'expanded_genres', 'rating'], content_columns = ['content'], id_column = 'movie_id'; """) kb_creation_query.fetch() print("Created knowledge base 'movies_kb'") except Exception as e: print(f"Knowledge base creation error or already exists: {e}")
You should receive the output:
Created knowledge base 'movies_kb'
Now let’s insert our movie data into this knowledge base:
from yaspin import yaspin try: with yaspin(text="Inserting data into knowledge base..."): insert_query = server.query(""" INSERT INTO movies_kb SELECT movie_id, genre, expanded_genres, rating, content FROM files.movies WHERE rating >= 7.5 USING track_column = movie_id """).fetch() print("✅ Data inserted successfully!") except Exception as e: print(f"❌ Insert error: {e}")
You should receive the output:
✅ Data inserted successfully
What’s happening here:
This is where the magic happens - we’re inserting data into our knowledge base, and MindsDB is automatically generating embeddings for each movie’s content using the OpenAI model we specified earlier. We’re filtering for movies with ratings of 7.5 or higher to focus on high-quality films. The track_column = movie_id parameter tells MindsDB to use the movie_id as the unique identifier for tracking and updating entries.
This operation may take a few minutes since it’s making API calls to OpenAI to generate embeddings for thousands of movie descriptions.
We verify the upload by counting the entries in our knowledge base:
row_count_df = server.query(""" SELECT COUNT(*) AS cnt FROM (SELECT id FROM movies_kb) AS t; """).fetch() row_count = int(row_count_df.at[0, 'cnt']) print(f"✅ movies_kb now contains {row_count:,} rows.")
Your output should be:
✅ movies_kb now contains 10,152 rows
The 10,152 rows confirm that all highly-rated movies (rating ≥ 7.5) have been successfully embedded and stored. Our knowledge base is now ready for semantic search queries!
Let’s see some data in the knowledge base:
search_query = server.query("SELECT * FROM movies_kb where content='Christmas' order by relevance desc") display(search_query.fetch())
| chunk_id | chunk_content | metadata | distance | relevance | |
|---|---|---|---|---|---|---|
0 | Pixi Post and the Gift Bringers - 2016 | Pixi Post and the Gift Bringers - 2016:content... | Christmas is on danger. Only Pixi Post can sav... | {"_chunk_index": 0, "_content_column": "conten... | 0.598186 | 0.625709 |
1 | Jingle Vingle the Movie - 2022 | Jingle Vingle the Movie - 2022:content:1of1:0t... | Presenting India's First Christmas Themed Movi... | {"_chunk_index": 0, "_content_column": "conten... | 0.609807 | 0.621192 |
2 | For Unto Us - 2021 | For Unto Us - 2021:content:1of1:0to96 | A musical portrayal of the nativity of Jesus C... | {"_chunk_index": 0, "_content_column": "conten... | 0.643808 | 0.608344 |
3 | Joyeux Noel - 2005 | Joyeux Noel - 2005:content:1of1:0to174 | In December 1914, an unofficial Christmas truc... | {"_chunk_index": 0, "_content_column": "conten... | 0.657826 | 0.603200 |
4 | Christmas Snow Angels - 2011 | Christmas Snow Angels - 2011:content:1of1:0to160 | A young girl is dealing with the death of a lo... | {"_chunk_index": 0, "_content_column": "conten... | 0.663354 | 0.601195 |
5 | Save Christmas - 2022 | Save Christmas - 2022:content:1of1:0to138 | Grumpy Dad dislikes Christmas while mum and ki... | {"_chunk_index": 0, "_content_column": "conten... | 0.665107 | 0.600562 |
6 | Beanie - 2022 | Beanie - 2022:content:1of1:0to230 | A boy who has nothing and a girl who seems to ... | {"_chunk_index": 0, "_content_column": "conten... | 0.666201 | 0.600168 |
7 | Carol of the Bells - 2022 | Carol of the Bells - 2022:content:1of1:0to223 | Immortalised as one of the most scintillating ... | {"_chunk_index": 0, "_content_column": "conten... | 0.667653 | 0.599645 |
8 | Winter Thaw - 2016 | Winter Thaw - 2016:content:1of1:0to103 | An old man comes to realize the mistakes he ha... | {"_chunk_index": 0, "_content_column": "conten... | 0.668738 | 0.599255 |
9 | Tis the Season - 1994 | Tis the Season - 1994:content:1of1:0to208 | A little girl, Heather, learns the real meanin... | {"_chunk_index": 0, "_content_column": "conten... | 0.669196 | 0.599091 |
Let’s see what’s inside a metadata column’s cell:
# Query to get full metadata content metadata_query = server.query(""" SELECT id, metadata FROM movies_kb WHERE content='Christmas' ORDER BY relevance DESC LIMIT 5 """).fetch() # Display full metadata without truncation import pandas as pd pd.set_option('display.max_colwidth', None) display(metadata_query) # Or print metadata for each row to see the complete JSON structure print("\nDetailed metadata for top results:") for idx, row in metadata_query.iterrows(): print(f"\n{row['id']}:") print(row['metadata'])
| metadata | |
|---|---|---|
0 | Pixi Post and the Gift Bringers - 2016 | {"_chunk_index": 0, "_content_column": "content", "_end_char": 51, "_original_doc_id": "Pixi Post and the Gift Bringers - 2016", "_original_row_index": "3912", "_source": "TextChunkingPreprocessor", "_start_char": 0, "_updated_at": "2025-10-14 18:17:11", "expanded_genres": "Animation, Adventure, Fantasy", "genre": "Fantasy", "rating": 7.9} |
1 | Jingle Vingle the Movie - 2022 | {"_chunk_index": 0, "_content_column": "content", "_end_char": 161, "_original_doc_id": "Jingle Vingle the Movie - 2022", "_original_row_index": "9700", "_source": "TextChunkingPreprocessor", "_start_char": 0, "_updated_at": "2025-10-14 18:17:11", "expanded_genres": "Family", "genre": "Family", "rating": 9.7} |
2 | For Unto Us - 2021 | {"_chunk_index": 0, "_content_column": "content", "_end_char": 96, "_original_doc_id": "For Unto Us - 2021", "_original_row_index": "4370", "_source": "TextChunkingPreprocessor", "_start_char": 0, "_updated_at": "2025-10-14 18:17:11", "expanded_genres": "Family", "genre": "Family", "rating": 9.1} |
3 | Joyeux Noel - 2005 | {"_chunk_index": 0, "_content_column": "content", "_end_char": 174, "_original_doc_id": "Joyeux Noel - 2005", "_original_row_index": "5021", "_source": "TextChunkingPreprocessor", "_start_char": 0, "_updated_at": "2025-10-14 18:17:11", "expanded_genres": "Drama, History, Music", "genre": "Romance", "rating": 7.7} |
4 | Christmas Snow Angels - 2011 | {"_chunk_index": 0, "_content_column": "content", "_end_char": 160, "_original_doc_id": "Christmas Snow Angels - 2011", "_original_row_index": "4510", "_source": "TextChunkingPreprocessor", "_start_char": 0, "_updated_at": "2025-10-14 18:17:11", "expanded_genres": "Family", "genre": "Family", "rating": 8.5} |
You will receive the output:
Detailed metadata for top results: Pixi Post and the Gift Bringers - 2016: {"_chunk_index": 0, "_content_column": "content", "_end_char": 51, "_original_doc_id": "Pixi Post and the Gift Bringers - 2016", "_original_row_index": "3912", "_source": "TextChunkingPreprocessor", "_start_char": 0, "_updated_at": "2025-10-14 18:17:11", "expanded_genres": "Animation, Adventure, Fantasy", "genre": "Fantasy", "rating": 7.9} Jingle Vingle the Movie - 2022: {"_chunk_index": 0, "_content_column": "content", "_end_char": 161, "_original_doc_id": "Jingle Vingle the Movie - 2022", "_original_row_index": "9700", "_source": "TextChunkingPreprocessor", "_start_char": 0, "_updated_at": "2025-10-14 18:17:11", "expanded_genres": "Family", "genre": "Family", "rating": 9.7} For Unto Us - 2021: {"_chunk_index": 0, "_content_column": "content", "_end_char": 96, "_original_doc_id": "For Unto Us - 2021", "_original_row_index": "4370", "_source": "TextChunkingPreprocessor", "_start_char": 0, "_updated_at": "2025-10-14 18:17:11", "expanded_genres": "Family", "genre": "Family", "rating": 9.1} Joyeux Noel - 2005: {"_chunk_index": 0, "_content_column": "content", "_end_char": 174, "_original_doc_id": "Joyeux Noel - 2005", "_original_row_index": "5021", "_source": "TextChunkingPreprocessor", "_start_char": 0, "_updated_at": "2025-10-14 18:17:11", "expanded_genres": "Drama, History, Music", "genre": "Romance", "rating": 7.7} Christmas Snow Angels - 2011: {"_chunk_index": 0, "_content_column": "content", "_end_char": 160, "_original_doc_id": "C
Understanding the metadata structure:
A chunk is a segment of text created when MindsDB breaks down longer content into smaller, searchable pieces to fit within the embedding model’s input limits. This chunking ensures searches can pinpoint specific passages within larger documents rather than only matching entire documents.
The metadata field contains two types of information:
System-generated fields (prefixed with underscores) that MindsDB automatically adds:
_chunk_index: The sequential position of this chunk (0 means it’s the first/only chunk)_content_column: Which source column contained the text (“content” in our case)_start_charand_end_char: Character positions showing where this chunk begins and ends in the original text (0 to 51 means a 51-character description)_original_doc_id: The complete document identifier with content column appended_original_row_index: The row number from the original dataset (row 3912)_source: The preprocessor used for chunking (“TextChunkingPreprocessor”)_updated_at: Timestamp of when this entry was inserted or updated
User-defined metadata columns that we specified during knowledge base creation:
genre: “Fantasy” - the primary genre we defined as metadataexpanded_genres: “Animation, Adventure, Fantasy” - the full genre listrating: 7.9 - the movie’s IMDB rating
This combined metadata enables powerful hybrid search - you can perform semantic searches on content while filtering by structured metadata fields like genre or rating thresholds. For example, you could search for “Christmas adventure stories” and filter only for Animation genre with ratings above 7.5.
5. Performing Semantic Searches with RAG
Now that our knowledge base is populated and indexed, let’s implement a complete Retrieval-Augmented Generation (RAG) workflow. RAG combines semantic search with large language models to answer questions based on your specific data - in our case, movie descriptions.
What is RAG?
RAG is a technique that enhances LLM responses by grounding them in retrieved, relevant documents from your knowledge base. Instead of relying solely on the model’s training data, RAG retrieves the most relevant chunks from your knowledge base and uses them as context for generating answers. This ensures responses are factually accurate and based on your actual data.
The RAG workflow:
import openai from IPython.display import display client = openai.OpenAI(api_key=openai_api_key) def answer_question_with_llm(question: str): # 1. Use the existing search_kb function to get the most relevant chunks. print(f"Searching knowledge base for: '{question}'\n") relevant_chunks_df = search_kb(question, limit=100) print("Found the following relevant chunks:") display(relevant_chunks_df[['id', 'chunk_content', 'relevance']]) # 2. Concatenate the 'chunk_content' to form a single context string. context = "\n---\n".join(relevant_chunks_df['chunk_content']) # 3. Create the prompt for the gpt-4o model. prompt = f""" You are a movie expert assistant. Based *only* on the following movie summaries (context), answer the user's question. If the context doesn't contain the answer, state that you cannot answer based on the provided information. CONTEXT: {context} QUESTION: {question} """ # 4. Call the OpenAI API to get the answer. print("\nSending request to GPT-4o to generate a definitive answer...") try: response = client.chat.completions.create( model="gpt-4o", messages=[ {"role": "system", "content": "You are a helpful assistant that answers questions about movies using only the provided context."}, {"role": "user", "content": prompt} ], temperature=0.0 # We want a factual answer based on the text ) answer = response.choices[0].message.content return answer except Exception as e: return f"An error occurred while calling the OpenAI API: {e}" user_question = "Who a boy must defend his home against on Christmas eve?" final_answer = answer_question_with_llm(user_question) print("\n--- Generated Answer ---") print(final_answer)
You should receive the following output:
Searching knowledge base for: 'Who a boy must defend his home against on Christmas eve?' SELECT * FROM movies_kb WHERE content = 'Who a boy must defend his home against on Christmas eve?' ORDER BY relevance DESC LIMIT 100; Found the following relevant chunks:
| chunk_content | relevance | |
|---|---|---|---|
0 | Snap - 2005 | A young boy must defend his house after his pa... | 0.704163 |
1 | Home Alone - 1990 | An eight-year-old troublemaker, mistakenly lef... | 0.687292 |
2 | Save Christmas - 2022 | Grumpy Dad dislikes Christmas while mum and ki... | 0.663474 |
3 | Sinterklaas and Het Pieten Duo_ Het Gestolen S... | This year everything seems to be according to ... | 0.651742 |
4 | Pixi Post and the Gift Bringers - 2016 | Christmas is on danger. Only Pixi Post can sav... | 0.644813 |
... | ... | ... | ... |
95 | Young Citizen Patriots_ Young Kid Ambassadors ... | Young Patriots for good versus evil. | 0.606097 |
96 | Kireedam - 1989 | The life of a young man turns upside down when... | 0.606093 |
97 | Fangs Vs. Spurs - 2016 | When revengeful vampires attack, a group of se... | 0.605888 |
98 | The Iron Giant - 1999 | A young boy befriends a giant robot from outer... | 0.605594 |
99 | Shoplifters - 2018 | A family of small-time crooks take in a child ... | 0.605376 |
100 rows × 3 columns Sending request to GPT-4o to generate a definitive answer... --- Generated Answer --- The boy must defend his home against a pair of burglars on Christmas Eve
What happened here:
This function implements a complete RAG pipeline in four steps:
Semantic Search: The knowledge base is queried with the natural language question. MindsDB’s semantic search retrieves the top 100 most relevant movie chunks, ranked by relevance score. Notice how the search found “Home Alone” (relevance: 0.687) even though our question didn’t mention the movie title - semantic search understood the meaning of “boy defending home on Christmas.”
Context Assembly: All retrieved chunk contents are concatenated into a single context string, separated by dividers. This context now contains relevant information from multiple movies.
Prompt Engineering: We construct a carefully crafted prompt that instructs GPT-4o to act as a movie expert and answer only based on the provided context. This grounding reduces the chance that the model will hallucinate or use information outside our knowledge base.
LLM Generation: The OpenAI API processes the prompt with temperature=0.0 (deterministic, factual responses) and generates an answer by synthesizing information from the retrieved chunks.
The power of RAG:
The final answer - “The boy must defend his home against a pair of burglars on Christmas Eve” - demonstrates RAG’s strength. The LLM successfully:
Identified the most relevant movie (Home Alone) from the semantic search results
Extracted the key information about burglars from the movie description
Synthesized a clear, concise answer grounded in our actual data
This RAG approach ensures answers are (almost) always based on your knowledge base rather than the model’s general training data, making it a great solution for domain-specific applications like customer support, internal documentation systems, or specialized research assistants.
Let’s wrap up this tutorial with one more query:
user_question = "What Anakin was lured into by Chancellor Palpatine?" final_answer = answer_question_with_llm(user_question) print("\n--- Generated Answer ---") print(final_answer)
The output:
Searching knowledge base for: 'What Anakin was lured into by Chancellor Palpatine?' SELECT * FROM movies_kb WHERE content = 'What Anakin was lured into by Chancellor Palpatine?' ORDER BY relevance DESC LIMIT 100; Found the following relevant chunks:
id | chunk_content | relevance | |
|---|---|---|---|
0 | Star Wars_ Episode III - Revenge of the Sith -... | Three years into the Clone Wars, Obi-Wan pursu... | 0.712999 |
1 | Sith Wars_ Episode I - The Return of the Sith ... | Emperor Palpatine reigns the galaxy, along wit... | 0.646388 |
2 | Sith Wars_ Episode II - Legacy of the Sith - 2022 | After the defeat at Agamar, Darth Vader discov... | 0.638359 |
3 | The Last Padawan 2 - 2021 | The Last Padawan is back with The Evil Empire ... | 0.631523 |
4 | Star Wars_ Episode VI - Return of the Jedi - 1983 | After rescuing Han Solo from Jabba the Hutt, t... | 0.625445 |
... | ... | ... | ... |
95 | Serenity - 2005 | The crew of the ship Serenity try to evade an ... | 0.570973 |
96 | Crackula Goes to Hollywood - 2015 | A mysterious man from Alaska, known to be from... | 0.570895 |
97 | Horseface 2_ Reverse the Curse - 2017 | Delshawn, "The Chosen One", is back in action,... | 0.570883 |
98 | Khamsa - The Well of Oblivion - 2022 | Down in a dark well, an amnesiac little boy ca... | 0.570599 |
99 | Ben-Hur - 1959 | After a Jewish prince is betrayed and sent int... | 0.570478 |
100 rows × 3 columns Sending request to GPT-4o to generate a definitive answer... --- Generated Answer --- Anakin was lured by Chancellor Palpatine into a sinister plot to rule the galaxy
Conclusion
Congratulations! You’ve successfully built a semantic search knowledge base with MindsDB that can understand and answer natural language questions about movies. Let’s recap what we’ve accomplished:
What you’ve built:
A knowledge base containing 10,152 high-quality movies with semantic embeddings
A complete RAG (Retrieval-Augmented Generation) pipeline that combines semantic search with LLM-powered question answering
A system that understands meaning, not just keywords - finding “Home Alone” when asked about “a boy defending his home on Christmas” and “Star Wars Episode III” when queried about “Anakin and Chancellor Palpatine”
Key takeaways:
Semantic search transcends keywords: MindsDB’s knowledge bases use embeddings to understand the meaning behind queries, enabling more intuitive and natural search experiences
Hybrid search combines the best of both worlds: By integrating semantic understanding with metadata filtering (genre, ratings, etc.), you can create powerful, precise queries
RAG grounds AI in your data: Instead of relying on potentially outdated or hallucinated information, RAG ensures answers are most of the time (LLMs always hallucinate, but grounding them in your factual data reduces hallucinations to a great extent) based on your actual knowledge base
Where to go from here:
This tutorial demonstrated the fundamentals, but knowledge bases can power much more:
Build chatbots that answer questions about your company’s documentation, policies, or products
Create recommendation systems that understand user preferences semantically
Develop research assistants for academic papers, legal documents, or technical manuals
Scale to production by connecting MindsDB to your existing databases, APIs, or data warehouses
The beauty of MindsDB is that you control it entirely through SQL - a familiar interface that makes advanced AI capabilities accessible without complex infrastructure or learning new APIs or domain-specific programming languages. Whether you’re working with customer support tickets, research papers, code repositories, or movie databases, the same principles apply.
Now it’s your turn to build something amazing with your own data!
You can also check out the full webinar, Fast‑Track Knowledge Bases: How to Build Semantic AI Search.
Products
Open Source
© 2026 All rights reserved by MindsDB.

Start conversational analytics with MindsDB
Production-ready infrastructure for agentic analytics
Start conversational analytics with MindsDB
Production-ready infrastructure for agentic analytics

Products
Open Source
© 2026 All rights reserved by MindsDB.

Products
Open Source
© 2026 All rights reserved by MindsDB.
Start conversational analytics with MindsDB
Production-ready infrastructure for agentic analytics