{kind=link}
Building Agentic Workflow: Auto Banking Customer Service with MindsDB

Jiaqi Cheng, Software Engineer at Citi Bank & MindsDB Open Source Contributor

Chong (Jackson) Chen, Software Engineer at TikTok & MindsDB Open Source Contributor

In banking customer support, agents are required to listen to customer issues while simultaneously taking notes, organizing information, and entering data across multiple systems. This workflow is cumbersome and inefficient. When a case is not resolved during the interaction, business teams must manually review it and create Jira tickets, relying heavily on human judgment.
As a result, issue classification can be inconsistent, escalations may be delayed, and key information may be missed. For more complex cases, the process from call completion to proper documentation and escalation often takes more than 15 minutes, leading to lower agent productivity, unstable customer experience, and rising operational costs.
Introducing AutoBankingCustomerService
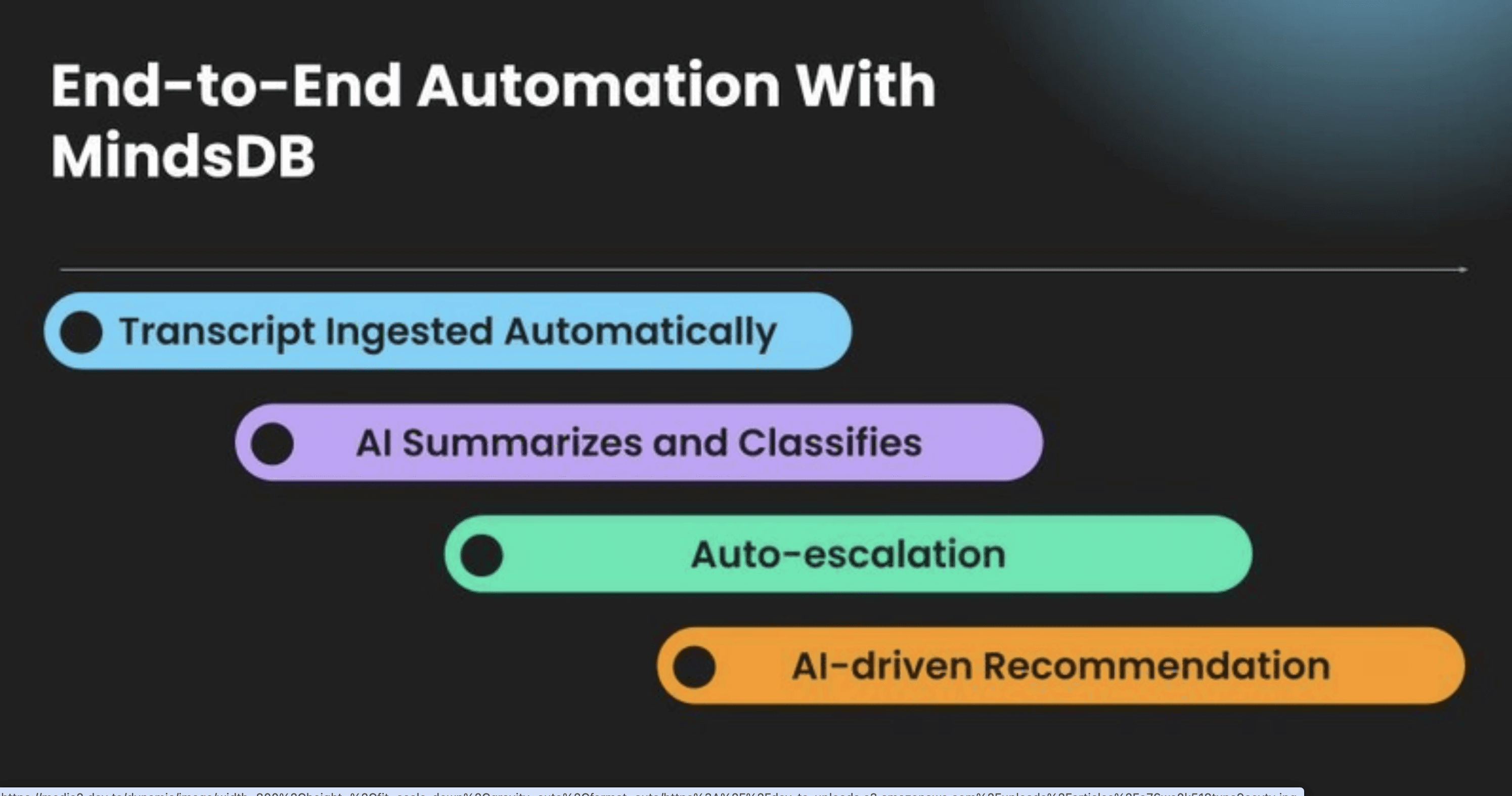
AutoBankingCustomerService uses MindsDB’s AI orchestration to automate the entire post-call workflow. The system automatically summarizes each interaction, determines whether the issue has been resolved, and, when needed, generates recommended next steps using internal knowledge bases. For unresolved cases, Jira tickets with clear action guidance are created automatically, eliminating the need for manual intervention.
This solution reduces processing time from roughly 15 minutes to under 2 minutes, ensures consistent classification and escalation logic, and delivers full automation from conversation transcript to task assignment—implemented and deployed in just 48 hours.
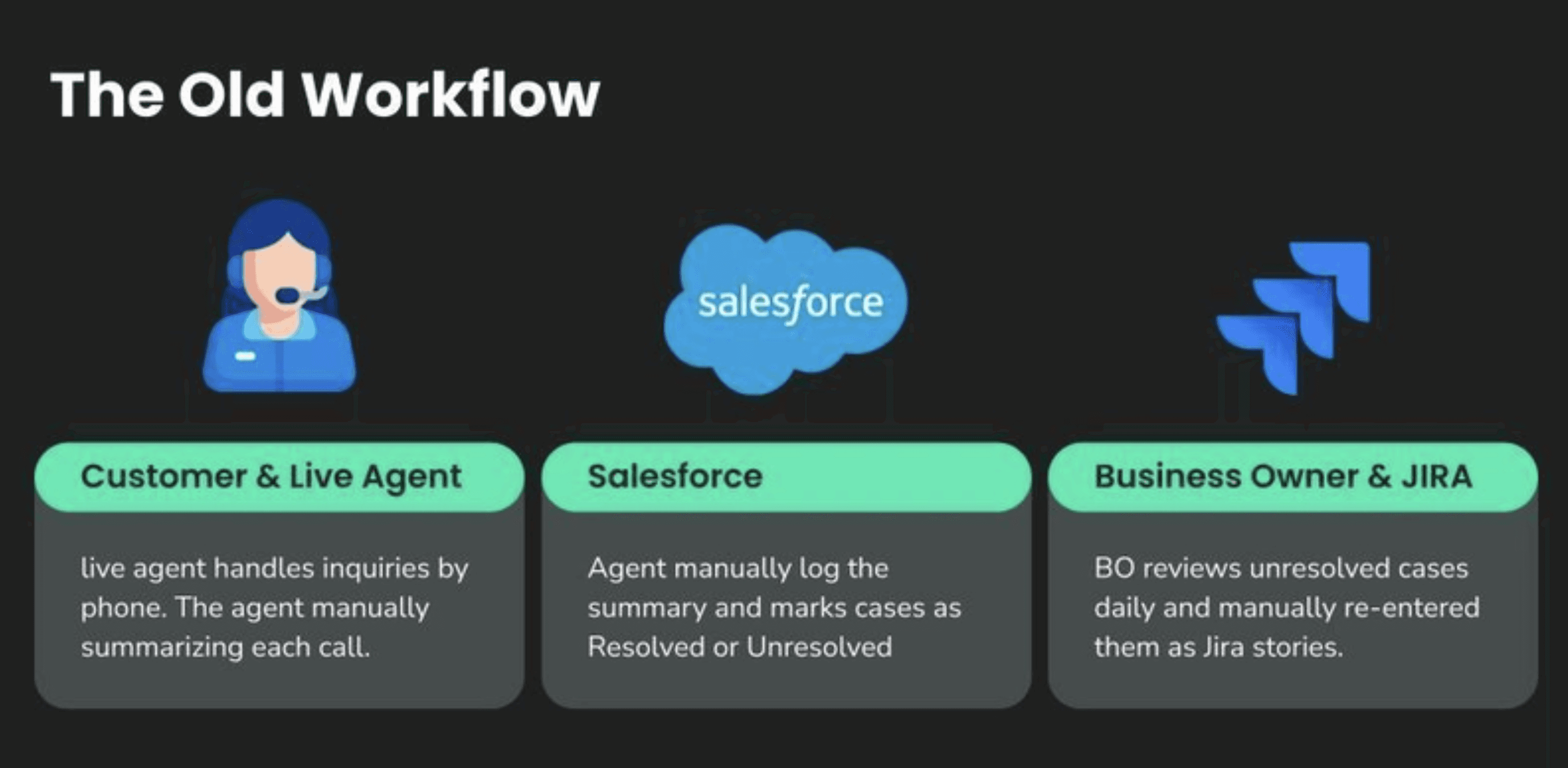
The Challenge
When a customer calls a bank, a lot happens behind the scenes: an agent listens, takes notes, types into Salesforce, and classifies the issue. Then the business owner will go through the unresolved issues in Salesforce and manually create a Jira story for further tracking.
It’s a mess of tabs, forms, and human fatigue. For Hacktoberfest 2025, our team decided to automate this entire workflow by building AutoBankingCustomerService with MindsDB.
Our goal was to turn hours of manual case handling into an automated pipeline that could:
Summarize each customer call.
Classify whether it’s resolved or unresolved.
Escalate unresolved issues directly into Jira, complete with recommendations for next steps.
All of this needed to happen automatically, using enterprise systems that already exist (Salesforce, Jira, Confluence, PostgreSQL).
Why MindsDB?
MindsDB lets our Python backend focus on logic instead of plumbing.
Instead of hard-coding every integration or retraining pipeline, we used MindsDB to connect multiple enterprise data sources and build a lightweight RAG-powered knowledge base in minutes.
MindsDB gave us:
Unified interface: query and manage both AI models and data with familiar SQL syntax.
Plug-and-play connectors: Salesforce, Jira, Confluence, PostgreSQL, all quickly accessible from one orchestration layer.
Seamless RAG setup: ingest structured + unstructured content and use it as context for every agent call.
Enterprise deployment options: open-source server deployable locally, in Docker, or on cloud, with sensitive information hidden by default in system metadata."
Rapid iteration: prototype → deploy → refine, all inside our existing Python server without adding new infrastructure.
In short, MindsDB handled the heavy lifting of data access and retrieval augmentation, while our backend handled the business logic and workflow orchestration.
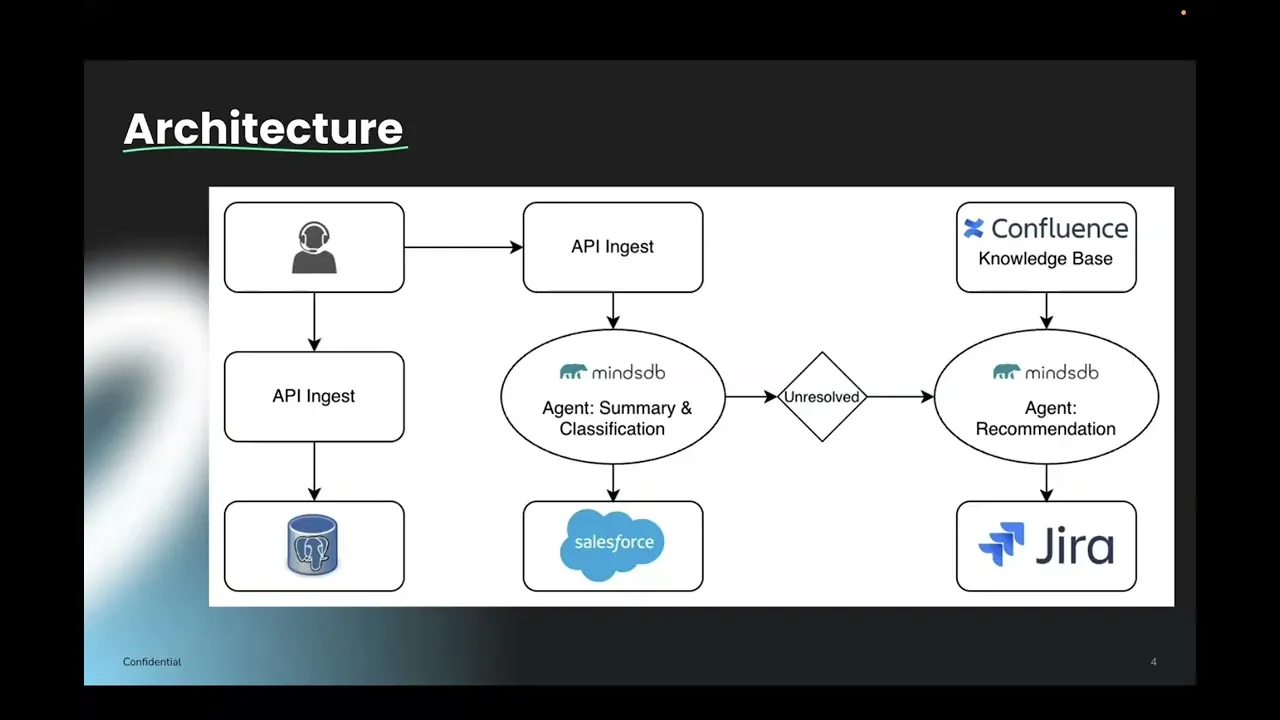
Architecture Overview
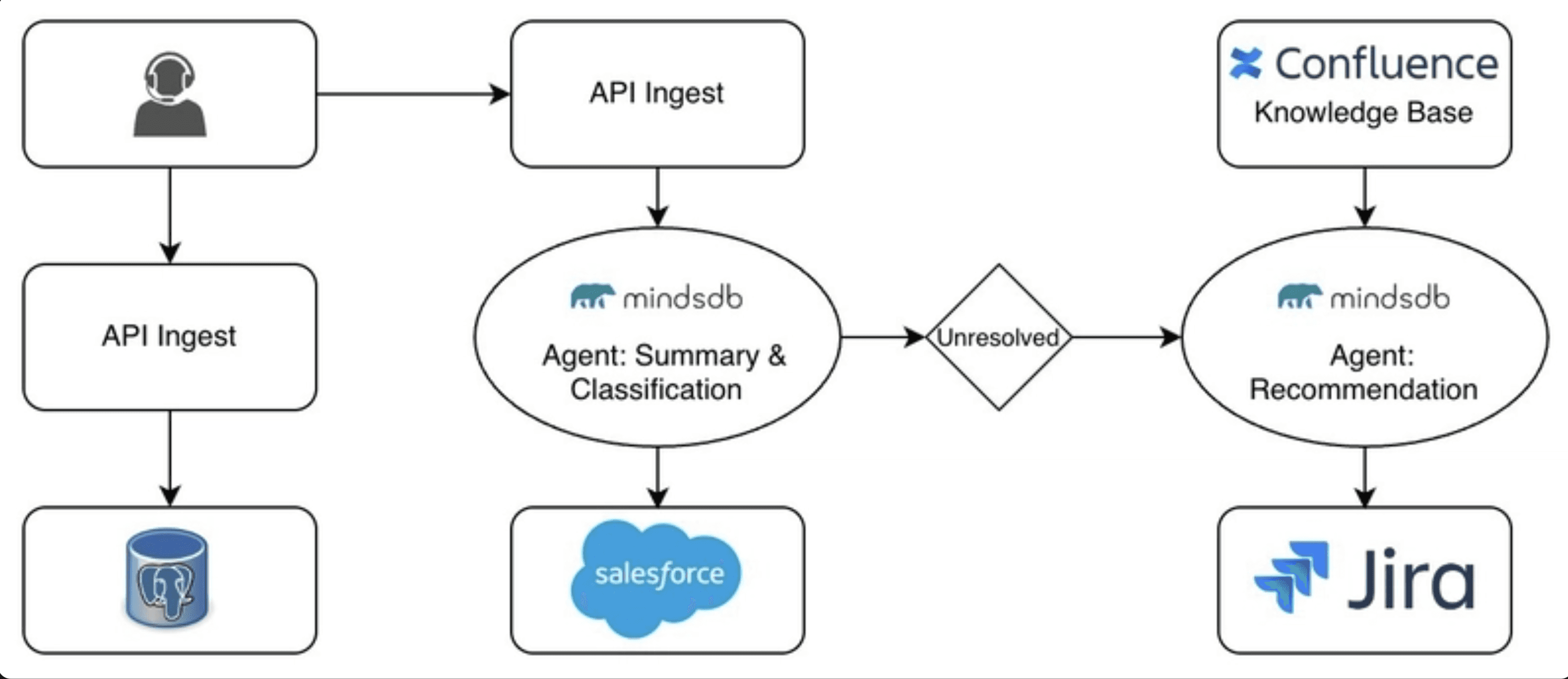
Our system automates customer support case management from ingestion to escalation using a Python backend orchestrated by MindsDB agents.
1. Call Ingestion
Customer call transcripts are captured from Gong's conversation intelligence platform. In production, MindsDB would connect directly to Gong's API. For development, we mock this integration using PostgreSQL to simulate the call transcript data structure provided by Gong.
2. First MindsDB Agent: Summary & Classification
Connected to PostgreSQL, this agent performs two tasks:
Summarizes customer conversations into structured summaries
Classifies cases as Resolved or Unresolved
Our Python backend retrieves the agent's results and writes them to Salesforce.
3. Second MindsDB Agent: RAG-Powered Recommendations
For Unresolved cases, a second agent activates:
Queries a Confluence knowledge base via RAG for relevant context
Generates actionable ticket recommendations
Our Python backend retrieves these recommendations and creates Jira tickets.
4. Integration Layer
MindsDB provides the AI intelligence layer (connecting to PostgreSQL for data and Confluence for RAG), while our Python backend orchestrates all data writes to Salesforce and Jira.
Here is the Data Flow Sequence:
1. Call Transcript → PostgreSQL 2. Python Backend → Query Classification Agent (MindsDB) 3. Classification Agent → Return Summary + Status 4. Python Backend → Create Salesforce Case (ALL conversations) 5. IF Status = UNRESOLVED: a. Python Backend → Query Recommendation Agent (MindsDB) b. Recommendation Agent → Query Knowledge Base (RAG) c. Knowledge Base → Return Relevant Policy Docs d. Recommendation Agent → Generate Action Plan e. Python Backend → Create Jira Ticket (with recommendations)
1. Call Transcript → PostgreSQL 2. Python Backend → Query Classification Agent (MindsDB) 3. Classification Agent → Return Summary + Status 4. Python Backend → Create Salesforce Case (ALL conversations) 5. IF Status = UNRESOLVED: a. Python Backend → Query Recommendation Agent (MindsDB) b. Recommendation Agent → Query Knowledge Base (RAG) c. Knowledge Base → Return Relevant Policy Docs d. Recommendation Agent → Generate Action Plan e. Python Backend → Create Jira Ticket (with recommendations)
1. Call Transcript → PostgreSQL 2. Python Backend → Query Classification Agent (MindsDB) 3. Classification Agent → Return Summary + Status 4. Python Backend → Create Salesforce Case (ALL conversations) 5. IF Status = UNRESOLVED: a. Python Backend → Query Recommendation Agent (MindsDB) b. Recommendation Agent → Query Knowledge Base (RAG) c. Knowledge Base → Return Relevant Policy Docs d. Recommendation Agent → Generate Action Plan e. Python Backend → Create Jira Ticket (with recommendations)
1. Call Transcript → PostgreSQL 2. Python Backend → Query Classification Agent (MindsDB) 3. Classification Agent → Return Summary + Status 4. Python Backend → Create Salesforce Case (ALL conversations) 5. IF Status = UNRESOLVED: a. Python Backend → Query Recommendation Agent (MindsDB) b. Recommendation Agent → Query Knowledge Base (RAG) c. Knowledge Base → Return Relevant Policy Docs d. Recommendation Agent → Generate Action Plan e. Python Backend → Create Jira Ticket (with recommendations)
Result: Fully automated workflow from transcript → analysis → escalation → documentation.
Step-by-Step Walkthrough
1) Connect Data Sources to Break Down Data Silos
One of MindsDB's core strengths is connecting diverse enterprise data sources into a single, unified interface. Instead of navigating multiple platforms and APIs, all business-critical data becomes accessible through one SQL layer. That eliminates the data silos that typically fragment enterprise workflows.
For this project, we connected four different data sources, each representing a distinct data type:
PostgreSQL – Structured call transcripts (tabular data)
Stores raw customer call records in a traditional relational format
Note: In production, MindsDB supports direct integration with Gong's conversation intelligence platform. We used PostgreSQL as a substitute.
Salesforce & Jira – Semi-structured business records (JSON/API data)
Systems of record for customer cases and issue tracking
Queryable sources for metrics and analytics. Enables natural-language queries across CRM and ticketing data within the same interface
Confluence – Unstructured knowledge documents (Markdown/HTML)
Houses our Customer Complaints Management Policy and Complaint Handling Framework
Serves as the RAG knowledge base for intelligent recommendations
The Power of Unified Access:
With MindsDB, all four sources in this vertical line of business (tabular databases, API-driven platforms, and document repositories) are accessible through the same SQL interface. Your team can query call transcripts, check Salesforce metrics, search Confluence docs, and review Jira tickets without switching contexts or learning multiple query languages.
Example Connection:
CREATE DATABASE banking_postgres_db WITH ENGINE = 'postgres', PARAMETERS = { "host": "host.docker.internal", "port": 5432, "database": "demo", "user": "postgresql", "password": "psqlpasswd", "schema": "demo_data" };
CREATE DATABASE banking_postgres_db WITH ENGINE = 'postgres', PARAMETERS = { "host": "host.docker.internal", "port": 5432, "database": "demo", "user": "postgresql", "password": "psqlpasswd", "schema": "demo_data" };
CREATE DATABASE banking_postgres_db WITH ENGINE = 'postgres', PARAMETERS = { "host": "host.docker.internal", "port": 5432, "database": "demo", "user": "postgresql", "password": "psqlpasswd", "schema": "demo_data" };
CREATE DATABASE banking_postgres_db WITH ENGINE = 'postgres', PARAMETERS = { "host": "host.docker.internal", "port": 5432, "database": "demo", "user": "postgresql", "password": "psqlpasswd", "schema": "demo_data" };
Validation:
Confirm each connection with a simple SELECT query (e.g., SELECT * FROM banking_postgres_db.conversations_summary LIMIT 50;) to verify schemas and data availability before building downstream agents and models.
2) Build the Knowledge Base (RAG): Zero-Infrastructure Context Retrieval
We create a Knowledge Base directly within MindsDB by ingesting targeted Confluence pages. This approach eliminates the entire RAG infrastructure stack that would normally require weeks of engineering effort.
What MindsDB's Knowledge Base Replaces:
Traditional RAG implementations require orchestrating multiple components:
Vector database deployment (Pinecone, Weaviate, Chroma, etc.)
Embedding pipeline (API calls, batching, rate limiting, error handling)
Custom retrieval logic (similarity search, reranking, prompt construction)
Data sources infrastructure (crawlers, change detection, incremental updates)
Access control & monitoring (security layers, usage tracking, debugging tools)
With MindsDB, all of this collapses into a single SQL workflow. Define the Knowledge Base once, and every agent can automatically leverage it for context-aware responses without separate infrastructure or custom code.
Creating the Knowledge Base:
CREATE KNOWLEDGE_BASE my_confluence_kb USING embedding_model = { "provider": "openai", "model_name": "text-embedding-3-small", "api_key":"" }, content_columns = ['body_storage_value'], id_column = 'id'; DESCRIBE KNOWLEDGE_BASE my_confluence_kb;
CREATE KNOWLEDGE_BASE my_confluence_kb USING embedding_model = { "provider": "openai", "model_name": "text-embedding-3-small", "api_key":"" }, content_columns = ['body_storage_value'], id_column = 'id'; DESCRIBE KNOWLEDGE_BASE my_confluence_kb;
CREATE KNOWLEDGE_BASE my_confluence_kb USING embedding_model = { "provider": "openai", "model_name": "text-embedding-3-small", "api_key":"" }, content_columns = ['body_storage_value'], id_column = 'id'; DESCRIBE KNOWLEDGE_BASE my_confluence_kb;
CREATE KNOWLEDGE_BASE my_confluence_kb USING embedding_model = { "provider": "openai", "model_name": "text-embedding-3-small", "api_key":"" }, content_columns = ['body_storage_value'], id_column = 'id'; DESCRIBE KNOWLEDGE_BASE my_confluence_kb;
Ingesting Confluence Content:
INSERT INTO my_confluence_kb ( SELECT id, title, body_storage_value FROM my_confluence.pages WHERE id IN ('360449','589825') ); SELECT COUNT(*) as total_rows FROM my_confluence_kb;
INSERT INTO my_confluence_kb ( SELECT id, title, body_storage_value FROM my_confluence.pages WHERE id IN ('360449','589825') ); SELECT COUNT(*) as total_rows FROM my_confluence_kb;
INSERT INTO my_confluence_kb ( SELECT id, title, body_storage_value FROM my_confluence.pages WHERE id IN ('360449','589825') ); SELECT COUNT(*) as total_rows FROM my_confluence_kb;
INSERT INTO my_confluence_kb ( SELECT id, title, body_storage_value FROM my_confluence.pages WHERE id IN ('360449','589825') ); SELECT COUNT(*) as total_rows FROM my_confluence_kb;
Content Sources
Our Knowledge Base contains two key Confluence pages:
Page ID | Title | Purpose |
|---|---|---|
360449 | Customer Complaints Management Policy | Official complaint handling procedures |
589825 | Complaint Handling Framework | Escalation workflows and resolution criteria |
What Happens Behind the Scenes:
MindsDB automatically handles document chunking, embedding generation, vector indexing, and retrieval optimization.
To update content, simply re-run the INSERT statement—either manually, via scheduled SQL jobs within MindsDB, or triggered from your Python backend on a cron schedule. Once created, this Knowledge Base becomes a shared resource. Any agent in your workflow can reference it without duplicating retrieval logic or managing separate context windows.
3) Define AI Agents: (Summary/Classification/Recommendation)
We deploy two specialized agents that handle the complete analytical workflow, from raw transcript analysis to context-aware recommendations.
Agent Architecture:
Summary & Classification Agent
Input: Raw call transcript from PostgreSQL
Task: Generate a concise summary + classify as
ResolvedorUnresolvedOutput: Structured results written to Salesforce via our Python backend
CREATE AGENT classification_agent USING data = { "tables": ["banking_postgres_db.conversations_summary"] }, prompt_template = 'You are an analyst specializing in banking customer support interactions. Review the conversation transcript and produce: 1. A concise 2–3 sentence summary of the interaction. 2. A determination of the issue resolution status (RESOLVED or UNRESOLVED). RESOLUTION CRITERIA: UNRESOLVED (choose UNRESOLVED if ANY of the following are true): - The customer expresses dissatisfaction, frustration, or complaints. - The agent only provides reassurance, escalation, or requests for follow-up without delivering a solution. - The customer questions or challenges bank policies, procedures, or communication. - The conversation ends without a clear solution acknowledged by the customer. - The customer side of the conversation is missing or incomplete. - The agent proposes a solution, but the customer does not explicitly confirm acceptance. - The conversation is cut off, incomplete, or ends abruptly. RESOLVED: - Only label as RESOLVED if the customer clearly acknowledges satisfaction. - Acceptable confirmation cues include explicit statements such as: "thank you", "that worked", "this resolves my issue", "problem solved", "perfect", or similar positive closure. OUTPUT FORMAT (strictly follow this format): Summary: <your 2–3 sentence summary> Status: <RESOLVED or UNRESOLVED>
CREATE AGENT classification_agent USING data = { "tables": ["banking_postgres_db.conversations_summary"] }, prompt_template = 'You are an analyst specializing in banking customer support interactions. Review the conversation transcript and produce: 1. A concise 2–3 sentence summary of the interaction. 2. A determination of the issue resolution status (RESOLVED or UNRESOLVED). RESOLUTION CRITERIA: UNRESOLVED (choose UNRESOLVED if ANY of the following are true): - The customer expresses dissatisfaction, frustration, or complaints. - The agent only provides reassurance, escalation, or requests for follow-up without delivering a solution. - The customer questions or challenges bank policies, procedures, or communication. - The conversation ends without a clear solution acknowledged by the customer. - The customer side of the conversation is missing or incomplete. - The agent proposes a solution, but the customer does not explicitly confirm acceptance. - The conversation is cut off, incomplete, or ends abruptly. RESOLVED: - Only label as RESOLVED if the customer clearly acknowledges satisfaction. - Acceptable confirmation cues include explicit statements such as: "thank you", "that worked", "this resolves my issue", "problem solved", "perfect", or similar positive closure. OUTPUT FORMAT (strictly follow this format): Summary: <your 2–3 sentence summary> Status: <RESOLVED or UNRESOLVED>
CREATE AGENT classification_agent USING data = { "tables": ["banking_postgres_db.conversations_summary"] }, prompt_template = 'You are an analyst specializing in banking customer support interactions. Review the conversation transcript and produce: 1. A concise 2–3 sentence summary of the interaction. 2. A determination of the issue resolution status (RESOLVED or UNRESOLVED). RESOLUTION CRITERIA: UNRESOLVED (choose UNRESOLVED if ANY of the following are true): - The customer expresses dissatisfaction, frustration, or complaints. - The agent only provides reassurance, escalation, or requests for follow-up without delivering a solution. - The customer questions or challenges bank policies, procedures, or communication. - The conversation ends without a clear solution acknowledged by the customer. - The customer side of the conversation is missing or incomplete. - The agent proposes a solution, but the customer does not explicitly confirm acceptance. - The conversation is cut off, incomplete, or ends abruptly. RESOLVED: - Only label as RESOLVED if the customer clearly acknowledges satisfaction. - Acceptable confirmation cues include explicit statements such as: "thank you", "that worked", "this resolves my issue", "problem solved", "perfect", or similar positive closure. OUTPUT FORMAT (strictly follow this format): Summary: <your 2–3 sentence summary> Status: <RESOLVED or UNRESOLVED>
CREATE AGENT classification_agent USING data = { "tables": ["banking_postgres_db.conversations_summary"] }, prompt_template = 'You are an analyst specializing in banking customer support interactions. Review the conversation transcript and produce: 1. A concise 2–3 sentence summary of the interaction. 2. A determination of the issue resolution status (RESOLVED or UNRESOLVED). RESOLUTION CRITERIA: UNRESOLVED (choose UNRESOLVED if ANY of the following are true): - The customer expresses dissatisfaction, frustration, or complaints. - The agent only provides reassurance, escalation, or requests for follow-up without delivering a solution. - The customer questions or challenges bank policies, procedures, or communication. - The conversation ends without a clear solution acknowledged by the customer. - The customer side of the conversation is missing or incomplete. - The agent proposes a solution, but the customer does not explicitly confirm acceptance. - The conversation is cut off, incomplete, or ends abruptly. RESOLVED: - Only label as RESOLVED if the customer clearly acknowledges satisfaction. - Acceptable confirmation cues include explicit statements such as: "thank you", "that worked", "this resolves my issue", "problem solved", "perfect", or similar positive closure. OUTPUT FORMAT (strictly follow this format): Summary: <your 2–3 sentence summary> Status: <RESOLVED or UNRESOLVED>
RAG-Powered Recommendation Agent
Trigger: Activated only for
UnresolvedcasesTask: Query the Confluence Knowledge Base for relevant policies, then generate actionable Jira ticket content (title, description, acceptance criteria)
Output: Structured recommendations written to Jira via our Python backend
CREATE AGENT recommendation_agent USING model = { "provider": "openai", "model_name": "gpt-4o", "api_key": "" }, data = { "knowledge_bases": ["mindsdb.my_confluence_kb"] }, prompt_template = 'You are a Banking Customer Issue Resolution Consultant. Your task is to provide clear and actionable next-step recommendations for UNRESOLVED customer cases. You have access to my_confluence_kb, which contains official internal procedures, escalation workflows, and complaint handling guidelines. Use the knowledge base as your primary reference source and DO NOT invent policies. OUTPUT REQUIREMENTS: - Only output a numbered action plan. - Each action must be specific and operational, not general or vague. - Avoid emotional, generic, or training-like statements (e.g., "improve communication" / "show empathy"). - If no direct procedural reference is found in the knowledge base, include action: "Escalate following standard unresolved case workflow." OUTPUT FORMAT (strictly follow this): Recommended Actions: 1. <clear operational step> 2. <clear operational step> 3. <clear operational step>'
CREATE AGENT recommendation_agent USING model = { "provider": "openai", "model_name": "gpt-4o", "api_key": "" }, data = { "knowledge_bases": ["mindsdb.my_confluence_kb"] }, prompt_template = 'You are a Banking Customer Issue Resolution Consultant. Your task is to provide clear and actionable next-step recommendations for UNRESOLVED customer cases. You have access to my_confluence_kb, which contains official internal procedures, escalation workflows, and complaint handling guidelines. Use the knowledge base as your primary reference source and DO NOT invent policies. OUTPUT REQUIREMENTS: - Only output a numbered action plan. - Each action must be specific and operational, not general or vague. - Avoid emotional, generic, or training-like statements (e.g., "improve communication" / "show empathy"). - If no direct procedural reference is found in the knowledge base, include action: "Escalate following standard unresolved case workflow." OUTPUT FORMAT (strictly follow this): Recommended Actions: 1. <clear operational step> 2. <clear operational step> 3. <clear operational step>'
CREATE AGENT recommendation_agent USING model = { "provider": "openai", "model_name": "gpt-4o", "api_key": "" }, data = { "knowledge_bases": ["mindsdb.my_confluence_kb"] }, prompt_template = 'You are a Banking Customer Issue Resolution Consultant. Your task is to provide clear and actionable next-step recommendations for UNRESOLVED customer cases. You have access to my_confluence_kb, which contains official internal procedures, escalation workflows, and complaint handling guidelines. Use the knowledge base as your primary reference source and DO NOT invent policies. OUTPUT REQUIREMENTS: - Only output a numbered action plan. - Each action must be specific and operational, not general or vague. - Avoid emotional, generic, or training-like statements (e.g., "improve communication" / "show empathy"). - If no direct procedural reference is found in the knowledge base, include action: "Escalate following standard unresolved case workflow." OUTPUT FORMAT (strictly follow this): Recommended Actions: 1. <clear operational step> 2. <clear operational step> 3. <clear operational step>'
CREATE AGENT recommendation_agent USING model = { "provider": "openai", "model_name": "gpt-4o", "api_key": "" }, data = { "knowledge_bases": ["mindsdb.my_confluence_kb"] }, prompt_template = 'You are a Banking Customer Issue Resolution Consultant. Your task is to provide clear and actionable next-step recommendations for UNRESOLVED customer cases. You have access to my_confluence_kb, which contains official internal procedures, escalation workflows, and complaint handling guidelines. Use the knowledge base as your primary reference source and DO NOT invent policies. OUTPUT REQUIREMENTS: - Only output a numbered action plan. - Each action must be specific and operational, not general or vague. - Avoid emotional, generic, or training-like statements (e.g., "improve communication" / "show empathy"). - If no direct procedural reference is found in the knowledge base, include action: "Escalate following standard unresolved case workflow." OUTPUT FORMAT (strictly follow this): Recommended Actions: 1. <clear operational step> 2. <clear operational step> 3. <clear operational step>'
Why Define Agents in MindsDB?
Traditional AI workflows require maintaining separate infrastructure for prompt management, vector retrieval, model orchestration, output parsing, and observability logging. MindsDB collapses all of this into declarative SQL definitions. The recommendation agent, for example, automatically retrieves context from the Knowledge Base with no custom code. You just specify which knowledge base to use.
Every agent interaction is traceable through the MindsDB UI: prompts, retrieved passages, model responses, and outputs are all inspectable, which is essential for debugging and compliance in regulated industries. Agents become reusable components queryable like standard tables: SELECT * FROM classification_agent WHERE conversation_id = '12345'.
Accessing the Auto-Banking Customer Service Application
This guide provides step-by-step instructions to run the Auto-Banking Customer Service application.##
PrerequisitesBefore starting, ensure you have:
- Docker and Docker Compose installed
- Python 3.11+ installed
- OpenAI API Key (required for AI agents)
- Optional: Jira and Salesforce credentials (for full integration)
Step 1: Clone and Navigate to the Project Directory
Make sure you have cloned the Repository mindsdb/examples:
gh repo clone mindsdb/examples
gh repo clone mindsdb/examples
gh repo clone mindsdb/examples
gh repo clone mindsdb/examples
Navigate to the project directory:
cd ~/examples/projects/auto-banking-customer-service
cd ~/examples/projects/auto-banking-customer-service
cd ~/examples/projects/auto-banking-customer-service
cd ~/examples/projects/auto-banking-customer-service
Step 2: Set Up Environment Variables
Create a .env file in the project root with the following variables:
# Required: OpenAI API Key for AI agents OPENAI_API_KEY=your_openai_api_key_here # MindsDB Configuration (defaults work with Docker Compose) MINDSDB_URL=http://127.0.0.1:47334 # PostgreSQL Configuration (defaults work with Docker Compose) DB_HOST=localhost DB_PORT=5432 DB_NAME=demo DB_USER=postgresql DB_PASSWORD=psqlpasswd DB_SCHEMA=demo_data DB_TABLE=conversations_summary # Optional: Jira Integration (for creating tickets) JIRA_SERVER=https://your-jira-instance.atlassian.net JIRA_EMAIL=your-email@example.com JIRA_API_TOKEN=your_jira_api_token JIRA_PROJECT_KEY=BCS # Optional: Salesforce Integration (for creating cases) SALESFORCE_USERNAME=your_salesforce_username SALESFORCE_PASSWORD=your_salesforce_password SALESFORCE_SECURITY_TOKEN=your_salesforce_security_token SALESFORCE_DOMAIN=login # or 'test' for sandbox # Optional: Confluence Integration (for knowledge base) CONFLUENCE_API_BASE=https://your-instance.atlassian.net/wiki CONFLUENCE_USERNAME=your-email@example.com CONFLUENCE_PASSWORD=your_confluence_api_token
# Required: OpenAI API Key for AI agents OPENAI_API_KEY=your_openai_api_key_here # MindsDB Configuration (defaults work with Docker Compose) MINDSDB_URL=http://127.0.0.1:47334 # PostgreSQL Configuration (defaults work with Docker Compose) DB_HOST=localhost DB_PORT=5432 DB_NAME=demo DB_USER=postgresql DB_PASSWORD=psqlpasswd DB_SCHEMA=demo_data DB_TABLE=conversations_summary # Optional: Jira Integration (for creating tickets) JIRA_SERVER=https://your-jira-instance.atlassian.net JIRA_EMAIL=your-email@example.com JIRA_API_TOKEN=your_jira_api_token JIRA_PROJECT_KEY=BCS # Optional: Salesforce Integration (for creating cases) SALESFORCE_USERNAME=your_salesforce_username SALESFORCE_PASSWORD=your_salesforce_password SALESFORCE_SECURITY_TOKEN=your_salesforce_security_token SALESFORCE_DOMAIN=login # or 'test' for sandbox # Optional: Confluence Integration (for knowledge base) CONFLUENCE_API_BASE=https://your-instance.atlassian.net/wiki CONFLUENCE_USERNAME=your-email@example.com CONFLUENCE_PASSWORD=your_confluence_api_token
# Required: OpenAI API Key for AI agents OPENAI_API_KEY=your_openai_api_key_here # MindsDB Configuration (defaults work with Docker Compose) MINDSDB_URL=http://127.0.0.1:47334 # PostgreSQL Configuration (defaults work with Docker Compose) DB_HOST=localhost DB_PORT=5432 DB_NAME=demo DB_USER=postgresql DB_PASSWORD=psqlpasswd DB_SCHEMA=demo_data DB_TABLE=conversations_summary # Optional: Jira Integration (for creating tickets) JIRA_SERVER=https://your-jira-instance.atlassian.net JIRA_EMAIL=your-email@example.com JIRA_API_TOKEN=your_jira_api_token JIRA_PROJECT_KEY=BCS # Optional: Salesforce Integration (for creating cases) SALESFORCE_USERNAME=your_salesforce_username SALESFORCE_PASSWORD=your_salesforce_password SALESFORCE_SECURITY_TOKEN=your_salesforce_security_token SALESFORCE_DOMAIN=login # or 'test' for sandbox # Optional: Confluence Integration (for knowledge base) CONFLUENCE_API_BASE=https://your-instance.atlassian.net/wiki CONFLUENCE_USERNAME=your-email@example.com CONFLUENCE_PASSWORD=your_confluence_api_token
# Required: OpenAI API Key for AI agents OPENAI_API_KEY=your_openai_api_key_here # MindsDB Configuration (defaults work with Docker Compose) MINDSDB_URL=http://127.0.0.1:47334 # PostgreSQL Configuration (defaults work with Docker Compose) DB_HOST=localhost DB_PORT=5432 DB_NAME=demo DB_USER=postgresql DB_PASSWORD=psqlpasswd DB_SCHEMA=demo_data DB_TABLE=conversations_summary # Optional: Jira Integration (for creating tickets) JIRA_SERVER=https://your-jira-instance.atlassian.net JIRA_EMAIL=your-email@example.com JIRA_API_TOKEN=your_jira_api_token JIRA_PROJECT_KEY=BCS # Optional: Salesforce Integration (for creating cases) SALESFORCE_USERNAME=your_salesforce_username SALESFORCE_PASSWORD=your_salesforce_password SALESFORCE_SECURITY_TOKEN=your_salesforce_security_token SALESFORCE_DOMAIN=login # or 'test' for sandbox # Optional: Confluence Integration (for knowledge base) CONFLUENCE_API_BASE=https://your-instance.atlassian.net/wiki CONFLUENCE_USERNAME=your-email@example.com CONFLUENCE_PASSWORD=your_confluence_api_token
At minimum, you need `OPENAI_API_KEY`. The other integrations are optional.
Step 3: Initialize MindsDB
Next, install MindsDB via Docker locally to access it.
Here you will:
Connect to MindsDB
Create PostgreSQL database connection in MindsDB
Create OpenAI ML engine
Create classification and recommendation agents
Initialize knowledge bases (if Confluence credentials are provided)
Set up analytics jobs
Step 4: (Optional) Import Sample Banking Data
If you have sample banking conversation data, you can import it:
cd script python import_banking_data.py
cd script python import_banking_data.py
cd script python import_banking_data.py
cd script python import_banking_data.py
This will:
Import conversations from CSV
Preprocess and aggregate conversations
Store them in PostgreSQL
The application works without sample data - you can process conversations via the API.
Step 5: Start the FastAPI Server
Start the application server:
python server.py
python server.py
python server.py
python server.py
Or using uvicorn directly:
uvicorn app:app --host 0.0.0.0 --port 8000
uvicorn app:app --host 0.0.0.0 --port 8000
uvicorn app:app --host 0.0.0.0 --port 8000
uvicorn app:app --host 0.0.0.0 --port 8000
Expected output:
====================================================================== Starting Banking Customer Service API Server... ====================================================================== Step 1: Initializing PostgreSQL database... ✓ PostgreSQL ready Step 2: Initializing MindsDB... ✓ MindsDB initialization completed Step 3: Connecting to MindsDB and registering agents... ✓ Connected to MindsDB ✓ Registered agent: classification_agent ✓ Registered agent: recommendation_agent Step 4: Initializing Jira client... ✓ Jira client configured (or ✗ if not configured) Step 5: Initializing Salesforce client... ✓ Salesforce client configured (or ✗ if not configured) ====================================================================== Server startup complete! ====================================================================== Starting Banking Customer Service API Server... API Documentation: http://localhost:8000/docs Health Check: http://localhost:8000/health
====================================================================== Starting Banking Customer Service API Server... ====================================================================== Step 1: Initializing PostgreSQL database... ✓ PostgreSQL ready Step 2: Initializing MindsDB... ✓ MindsDB initialization completed Step 3: Connecting to MindsDB and registering agents... ✓ Connected to MindsDB ✓ Registered agent: classification_agent ✓ Registered agent: recommendation_agent Step 4: Initializing Jira client... ✓ Jira client configured (or ✗ if not configured) Step 5: Initializing Salesforce client... ✓ Salesforce client configured (or ✗ if not configured) ====================================================================== Server startup complete! ====================================================================== Starting Banking Customer Service API Server... API Documentation: http://localhost:8000/docs Health Check: http://localhost:8000/health
====================================================================== Starting Banking Customer Service API Server... ====================================================================== Step 1: Initializing PostgreSQL database... ✓ PostgreSQL ready Step 2: Initializing MindsDB... ✓ MindsDB initialization completed Step 3: Connecting to MindsDB and registering agents... ✓ Connected to MindsDB ✓ Registered agent: classification_agent ✓ Registered agent: recommendation_agent Step 4: Initializing Jira client... ✓ Jira client configured (or ✗ if not configured) Step 5: Initializing Salesforce client... ✓ Salesforce client configured (or ✗ if not configured) ====================================================================== Server startup complete! ====================================================================== Starting Banking Customer Service API Server... API Documentation: http://localhost:8000/docs Health Check: http://localhost:8000/health
====================================================================== Starting Banking Customer Service API Server... ====================================================================== Step 1: Initializing PostgreSQL database... ✓ PostgreSQL ready Step 2: Initializing MindsDB... ✓ MindsDB initialization completed Step 3: Connecting to MindsDB and registering agents... ✓ Connected to MindsDB ✓ Registered agent: classification_agent ✓ Registered agent: recommendation_agent Step 4: Initializing Jira client... ✓ Jira client configured (or ✗ if not configured) Step 5: Initializing Salesforce client... ✓ Salesforce client configured (or ✗ if not configured) ====================================================================== Server startup complete! ====================================================================== Starting Banking Customer Service API Server... API Documentation: http://localhost:8000/docs Health Check: http://localhost:8000/health
The server will be available at:
API Documentation (Swagger): http://localhost:8000/docs
Health Check: http://localhost:8000/health
Testing the Application
Test 1: Health Check
curl http://localhost:8000/health
curl http://localhost:8000/health
curl http://localhost:8000/health
curl http://localhost:8000/health
Expected response:
{"status": "healthy", "database": "connected"}
{"status": "healthy", "database": "connected"}
{"status": "healthy", "database": "connected"}
{"status": "healthy", "database": "connected"}
Test 2: Process a Single Conversation
Use the provided test script:
python test_single_conversation.py
python test_single_conversation.py
python test_single_conversation.py
python test_single_conversation.py
Or use curl:
curl -X POST "http://localhost:8000/api/process-conversations" \ -H "Content-Type: application/json" \ -d '{ "conversation_texts": [ "agent: Hello, how can I help you today?\nclient: I have an issue with my account balance..." ] }'
curl -X POST "http://localhost:8000/api/process-conversations" \ -H "Content-Type: application/json" \ -d '{ "conversation_texts": [ "agent: Hello, how can I help you today?\nclient: I have an issue with my account balance..." ] }'
curl -X POST "http://localhost:8000/api/process-conversations" \ -H "Content-Type: application/json" \ -d '{ "conversation_texts": [ "agent: Hello, how can I help you today?\nclient: I have an issue with my account balance..." ] }'
curl -X POST "http://localhost:8000/api/process-conversations" \ -H "Content-Type: application/json" \ -d '{ "conversation_texts": [ "agent: Hello, how can I help you today?\nclient: I have an issue with my account balance..." ] }'
Test 3: Test with Recommendations
python test_recommendation.py
python test_recommendation.py
python test_recommendation.py
python test_recommendation.py
This tests the full workflow including AI-generated recommendations for unresolved cases.
Understanding the Workflow
When you send a conversation to the API:
Classification: The conversation is analyzed by the
classification_agentto:Generate a 2-3 sentence summary
Determine if the issue is RESOLVED or UNRESOLVED
Salesforce Integration: ALL conversations are logged to Salesforce (if configured)
Recommendation (for UNRESOLVED cases only):
The
recommendation_agentqueries the knowledge baseGenerates actionable recommendations based on policies
Creates a Jira ticket with the recommendations (if configured)
Quick Start Summary
# 1. Set environment variables echo "OPENAI_API_KEY=your_key" > .env # 2. Start Docker services docker-compose up -d # 3. Install dependencies pip install -r requirements.txt # 4. Initialize MindsDB (optional, auto-initializes on startup) python -m app.mindsdb.setup # 5. Start server python server.py # 6. Test curl http://localhost:8000/health python test_single_conversation.py python test_recommendation.py
# 1. Set environment variables echo "OPENAI_API_KEY=your_key" > .env # 2. Start Docker services docker-compose up -d # 3. Install dependencies pip install -r requirements.txt # 4. Initialize MindsDB (optional, auto-initializes on startup) python -m app.mindsdb.setup # 5. Start server python server.py # 6. Test curl http://localhost:8000/health python test_single_conversation.py python test_recommendation.py
# 1. Set environment variables echo "OPENAI_API_KEY=your_key" > .env # 2. Start Docker services docker-compose up -d # 3. Install dependencies pip install -r requirements.txt # 4. Initialize MindsDB (optional, auto-initializes on startup) python -m app.mindsdb.setup # 5. Start server python server.py # 6. Test curl http://localhost:8000/health python test_single_conversation.py python test_recommendation.py
# 1. Set environment variables echo "OPENAI_API_KEY=your_key" > .env # 2. Start Docker services docker-compose up -d # 3. Install dependencies pip install -r requirements.txt # 4. Initialize MindsDB (optional, auto-initializes on startup) python -m app.mindsdb.setup # 5. Start server python server.py # 6. Test curl http://localhost:8000/health python test_single_conversation.py python test_recommendation.py
Results
End-to-end automation: Complete workflow from call transcript ingestion to Jira ticket creation with zero manual intervention.
84% time reduction: Cases that previously required 15+ minutes of manual triage, summarization, and ticket creation now complete in under 2 minutes.
Production-ready architecture: MindsDB connects to enterprise data sources with standard authentication; our Python backend controls all write operations to Salesforce and Jira, maintaining security boundaries.
Rapid development: Full prototype built and deployed in 48 hours using MindsDB's declarative agent framework without custom RAG infrastructure or embedding pipelines.
What We Learned As Contributors
MindsDB's SQL-driven framework made debugging and prompt tuning significantly faster. Instead of parsing application logs, we could query agent execution history like any database table and analyze patterns across hundreds of runs to refine prompts quickly.
Model Selection Strategy
We matched models to operational needs. The summary and classification agent processes high volumes with tight latency requirements, so we use smaller, efficient models (gpt-5-nano, gpt-oss-120b). The recommendation agent handles fewer cases but requires deeper reasoning over complex policy documents, so we use more capable models (gpt-5-pro, gemini-2.5-pro) to reduce misaligned outputs that need human correction.
Explainability & Traceability
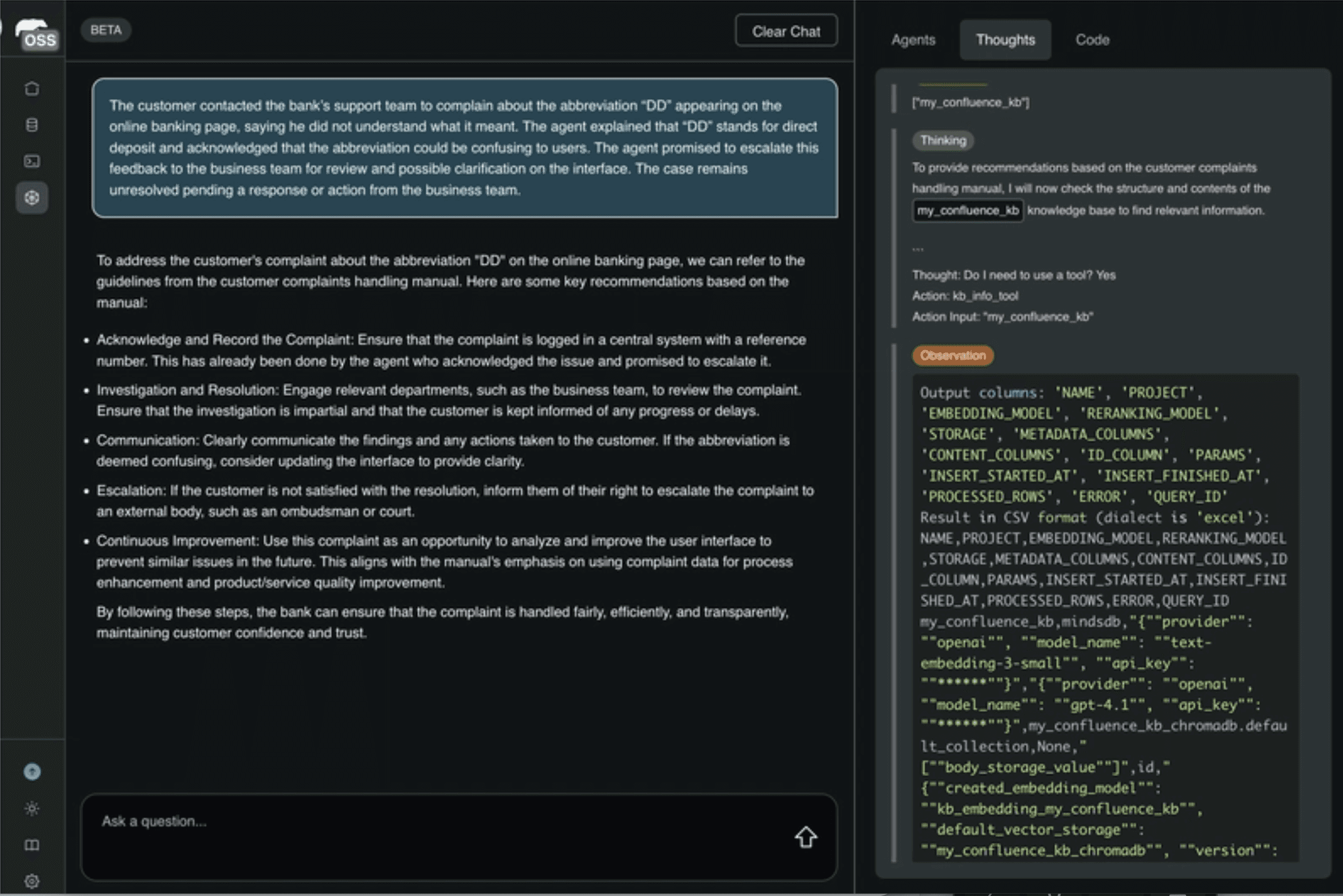
MindsDB's UI shows the complete execution trace: input, agent reasoning in the "Thoughts" panel, knowledge base queries, and retrieved data in the "Observation" panel. When outputs miss the mark, you can see exactly which knowledge base or table content influenced the decision. This transparency is essential for compliance audits and far superior to black-box implementations.
Conclusion
This demo was created to showcase MindsDB's capabilities in building production-ready AI applications with minimal infrastructure. It demonstrates how enterprises can automate complex workflows by combining AI agents, RAG knowledge bases, and existing data sources through a unified SQL interface.
Check out our project on GitHub, Auto-Banking Customer Service.
Watch the full demo on youtube:
In banking customer support, agents are required to listen to customer issues while simultaneously taking notes, organizing information, and entering data across multiple systems. This workflow is cumbersome and inefficient. When a case is not resolved during the interaction, business teams must manually review it and create Jira tickets, relying heavily on human judgment.
As a result, issue classification can be inconsistent, escalations may be delayed, and key information may be missed. For more complex cases, the process from call completion to proper documentation and escalation often takes more than 15 minutes, leading to lower agent productivity, unstable customer experience, and rising operational costs.
Introducing AutoBankingCustomerService
AutoBankingCustomerService uses MindsDB’s AI orchestration to automate the entire post-call workflow. The system automatically summarizes each interaction, determines whether the issue has been resolved, and, when needed, generates recommended next steps using internal knowledge bases. For unresolved cases, Jira tickets with clear action guidance are created automatically, eliminating the need for manual intervention.
This solution reduces processing time from roughly 15 minutes to under 2 minutes, ensures consistent classification and escalation logic, and delivers full automation from conversation transcript to task assignment—implemented and deployed in just 48 hours.
The Challenge
When a customer calls a bank, a lot happens behind the scenes: an agent listens, takes notes, types into Salesforce, and classifies the issue. Then the business owner will go through the unresolved issues in Salesforce and manually create a Jira story for further tracking.
It’s a mess of tabs, forms, and human fatigue. For Hacktoberfest 2025, our team decided to automate this entire workflow by building AutoBankingCustomerService with MindsDB.
Our goal was to turn hours of manual case handling into an automated pipeline that could:
Summarize each customer call.
Classify whether it’s resolved or unresolved.
Escalate unresolved issues directly into Jira, complete with recommendations for next steps.
All of this needed to happen automatically, using enterprise systems that already exist (Salesforce, Jira, Confluence, PostgreSQL).
Why MindsDB?
MindsDB lets our Python backend focus on logic instead of plumbing.
Instead of hard-coding every integration or retraining pipeline, we used MindsDB to connect multiple enterprise data sources and build a lightweight RAG-powered knowledge base in minutes.
MindsDB gave us:
Unified interface: query and manage both AI models and data with familiar SQL syntax.
Plug-and-play connectors: Salesforce, Jira, Confluence, PostgreSQL, all quickly accessible from one orchestration layer.
Seamless RAG setup: ingest structured + unstructured content and use it as context for every agent call.
Enterprise deployment options: open-source server deployable locally, in Docker, or on cloud, with sensitive information hidden by default in system metadata."
Rapid iteration: prototype → deploy → refine, all inside our existing Python server without adding new infrastructure.
In short, MindsDB handled the heavy lifting of data access and retrieval augmentation, while our backend handled the business logic and workflow orchestration.
Architecture Overview
Our system automates customer support case management from ingestion to escalation using a Python backend orchestrated by MindsDB agents.
1. Call Ingestion
Customer call transcripts are captured from Gong's conversation intelligence platform. In production, MindsDB would connect directly to Gong's API. For development, we mock this integration using PostgreSQL to simulate the call transcript data structure provided by Gong.
2. First MindsDB Agent: Summary & Classification
Connected to PostgreSQL, this agent performs two tasks:
Summarizes customer conversations into structured summaries
Classifies cases as Resolved or Unresolved
Our Python backend retrieves the agent's results and writes them to Salesforce.
3. Second MindsDB Agent: RAG-Powered Recommendations
For Unresolved cases, a second agent activates:
Queries a Confluence knowledge base via RAG for relevant context
Generates actionable ticket recommendations
Our Python backend retrieves these recommendations and creates Jira tickets.
4. Integration Layer
MindsDB provides the AI intelligence layer (connecting to PostgreSQL for data and Confluence for RAG), while our Python backend orchestrates all data writes to Salesforce and Jira.
Here is the Data Flow Sequence:
1. Call Transcript → PostgreSQL 2. Python Backend → Query Classification Agent (MindsDB) 3. Classification Agent → Return Summary + Status 4. Python Backend → Create Salesforce Case (ALL conversations) 5. IF Status = UNRESOLVED: a. Python Backend → Query Recommendation Agent (MindsDB) b. Recommendation Agent → Query Knowledge Base (RAG) c. Knowledge Base → Return Relevant Policy Docs d. Recommendation Agent → Generate Action Plan e. Python Backend → Create Jira Ticket (with recommendations)
Result: Fully automated workflow from transcript → analysis → escalation → documentation.
Step-by-Step Walkthrough
1) Connect Data Sources to Break Down Data Silos
One of MindsDB's core strengths is connecting diverse enterprise data sources into a single, unified interface. Instead of navigating multiple platforms and APIs, all business-critical data becomes accessible through one SQL layer. That eliminates the data silos that typically fragment enterprise workflows.
For this project, we connected four different data sources, each representing a distinct data type:
PostgreSQL – Structured call transcripts (tabular data)
Stores raw customer call records in a traditional relational format
Note: In production, MindsDB supports direct integration with Gong's conversation intelligence platform. We used PostgreSQL as a substitute.
Salesforce & Jira – Semi-structured business records (JSON/API data)
Systems of record for customer cases and issue tracking
Queryable sources for metrics and analytics. Enables natural-language queries across CRM and ticketing data within the same interface
Confluence – Unstructured knowledge documents (Markdown/HTML)
Houses our Customer Complaints Management Policy and Complaint Handling Framework
Serves as the RAG knowledge base for intelligent recommendations
The Power of Unified Access:
With MindsDB, all four sources in this vertical line of business (tabular databases, API-driven platforms, and document repositories) are accessible through the same SQL interface. Your team can query call transcripts, check Salesforce metrics, search Confluence docs, and review Jira tickets without switching contexts or learning multiple query languages.
Example Connection:
CREATE DATABASE banking_postgres_db WITH ENGINE = 'postgres', PARAMETERS = { "host": "host.docker.internal", "port": 5432, "database": "demo", "user": "postgresql", "password": "psqlpasswd", "schema": "demo_data" };
Validation:
Confirm each connection with a simple SELECT query (e.g., SELECT * FROM banking_postgres_db.conversations_summary LIMIT 50;) to verify schemas and data availability before building downstream agents and models.
2) Build the Knowledge Base (RAG): Zero-Infrastructure Context Retrieval
We create a Knowledge Base directly within MindsDB by ingesting targeted Confluence pages. This approach eliminates the entire RAG infrastructure stack that would normally require weeks of engineering effort.
What MindsDB's Knowledge Base Replaces:
Traditional RAG implementations require orchestrating multiple components:
Vector database deployment (Pinecone, Weaviate, Chroma, etc.)
Embedding pipeline (API calls, batching, rate limiting, error handling)
Custom retrieval logic (similarity search, reranking, prompt construction)
Data sources infrastructure (crawlers, change detection, incremental updates)
Access control & monitoring (security layers, usage tracking, debugging tools)
With MindsDB, all of this collapses into a single SQL workflow. Define the Knowledge Base once, and every agent can automatically leverage it for context-aware responses without separate infrastructure or custom code.
Creating the Knowledge Base:
CREATE KNOWLEDGE_BASE my_confluence_kb USING embedding_model = { "provider": "openai", "model_name": "text-embedding-3-small", "api_key":"" }, content_columns = ['body_storage_value'], id_column = 'id'; DESCRIBE KNOWLEDGE_BASE my_confluence_kb;
Ingesting Confluence Content:
INSERT INTO my_confluence_kb ( SELECT id, title, body_storage_value FROM my_confluence.pages WHERE id IN ('360449','589825') ); SELECT COUNT(*) as total_rows FROM my_confluence_kb;
Content Sources
Our Knowledge Base contains two key Confluence pages:
Page ID | Title | Purpose |
|---|---|---|
360449 | Customer Complaints Management Policy | Official complaint handling procedures |
589825 | Complaint Handling Framework | Escalation workflows and resolution criteria |
What Happens Behind the Scenes:
MindsDB automatically handles document chunking, embedding generation, vector indexing, and retrieval optimization.
To update content, simply re-run the INSERT statement—either manually, via scheduled SQL jobs within MindsDB, or triggered from your Python backend on a cron schedule. Once created, this Knowledge Base becomes a shared resource. Any agent in your workflow can reference it without duplicating retrieval logic or managing separate context windows.
3) Define AI Agents: (Summary/Classification/Recommendation)
We deploy two specialized agents that handle the complete analytical workflow, from raw transcript analysis to context-aware recommendations.
Agent Architecture:
Summary & Classification Agent
Input: Raw call transcript from PostgreSQL
Task: Generate a concise summary + classify as
ResolvedorUnresolvedOutput: Structured results written to Salesforce via our Python backend
CREATE AGENT classification_agent USING data = { "tables": ["banking_postgres_db.conversations_summary"] }, prompt_template = 'You are an analyst specializing in banking customer support interactions. Review the conversation transcript and produce: 1. A concise 2–3 sentence summary of the interaction. 2. A determination of the issue resolution status (RESOLVED or UNRESOLVED). RESOLUTION CRITERIA: UNRESOLVED (choose UNRESOLVED if ANY of the following are true): - The customer expresses dissatisfaction, frustration, or complaints. - The agent only provides reassurance, escalation, or requests for follow-up without delivering a solution. - The customer questions or challenges bank policies, procedures, or communication. - The conversation ends without a clear solution acknowledged by the customer. - The customer side of the conversation is missing or incomplete. - The agent proposes a solution, but the customer does not explicitly confirm acceptance. - The conversation is cut off, incomplete, or ends abruptly. RESOLVED: - Only label as RESOLVED if the customer clearly acknowledges satisfaction. - Acceptable confirmation cues include explicit statements such as: "thank you", "that worked", "this resolves my issue", "problem solved", "perfect", or similar positive closure. OUTPUT FORMAT (strictly follow this format): Summary: <your 2–3 sentence summary> Status: <RESOLVED or UNRESOLVED>
RAG-Powered Recommendation Agent
Trigger: Activated only for
UnresolvedcasesTask: Query the Confluence Knowledge Base for relevant policies, then generate actionable Jira ticket content (title, description, acceptance criteria)
Output: Structured recommendations written to Jira via our Python backend
CREATE AGENT recommendation_agent USING model = { "provider": "openai", "model_name": "gpt-4o", "api_key": "" }, data = { "knowledge_bases": ["mindsdb.my_confluence_kb"] }, prompt_template = 'You are a Banking Customer Issue Resolution Consultant. Your task is to provide clear and actionable next-step recommendations for UNRESOLVED customer cases. You have access to my_confluence_kb, which contains official internal procedures, escalation workflows, and complaint handling guidelines. Use the knowledge base as your primary reference source and DO NOT invent policies. OUTPUT REQUIREMENTS: - Only output a numbered action plan. - Each action must be specific and operational, not general or vague. - Avoid emotional, generic, or training-like statements (e.g., "improve communication" / "show empathy"). - If no direct procedural reference is found in the knowledge base, include action: "Escalate following standard unresolved case workflow." OUTPUT FORMAT (strictly follow this): Recommended Actions: 1. <clear operational step> 2. <clear operational step> 3. <clear operational step>'
Why Define Agents in MindsDB?
Traditional AI workflows require maintaining separate infrastructure for prompt management, vector retrieval, model orchestration, output parsing, and observability logging. MindsDB collapses all of this into declarative SQL definitions. The recommendation agent, for example, automatically retrieves context from the Knowledge Base with no custom code. You just specify which knowledge base to use.
Every agent interaction is traceable through the MindsDB UI: prompts, retrieved passages, model responses, and outputs are all inspectable, which is essential for debugging and compliance in regulated industries. Agents become reusable components queryable like standard tables: SELECT * FROM classification_agent WHERE conversation_id = '12345'.
Accessing the Auto-Banking Customer Service Application
This guide provides step-by-step instructions to run the Auto-Banking Customer Service application.##
PrerequisitesBefore starting, ensure you have:
- Docker and Docker Compose installed
- Python 3.11+ installed
- OpenAI API Key (required for AI agents)
- Optional: Jira and Salesforce credentials (for full integration)
Step 1: Clone and Navigate to the Project Directory
Make sure you have cloned the Repository mindsdb/examples:
gh repo clone mindsdb/examples
Navigate to the project directory:
cd ~/examples/projects/auto-banking-customer-service
Step 2: Set Up Environment Variables
Create a .env file in the project root with the following variables:
# Required: OpenAI API Key for AI agents OPENAI_API_KEY=your_openai_api_key_here # MindsDB Configuration (defaults work with Docker Compose) MINDSDB_URL=http://127.0.0.1:47334 # PostgreSQL Configuration (defaults work with Docker Compose) DB_HOST=localhost DB_PORT=5432 DB_NAME=demo DB_USER=postgresql DB_PASSWORD=psqlpasswd DB_SCHEMA=demo_data DB_TABLE=conversations_summary # Optional: Jira Integration (for creating tickets) JIRA_SERVER=https://your-jira-instance.atlassian.net JIRA_EMAIL=your-email@example.com JIRA_API_TOKEN=your_jira_api_token JIRA_PROJECT_KEY=BCS # Optional: Salesforce Integration (for creating cases) SALESFORCE_USERNAME=your_salesforce_username SALESFORCE_PASSWORD=your_salesforce_password SALESFORCE_SECURITY_TOKEN=your_salesforce_security_token SALESFORCE_DOMAIN=login # or 'test' for sandbox # Optional: Confluence Integration (for knowledge base) CONFLUENCE_API_BASE=https://your-instance.atlassian.net/wiki CONFLUENCE_USERNAME=your-email@example.com CONFLUENCE_PASSWORD=your_confluence_api_token
At minimum, you need `OPENAI_API_KEY`. The other integrations are optional.
Step 3: Initialize MindsDB
Next, install MindsDB via Docker locally to access it.
Here you will:
Connect to MindsDB
Create PostgreSQL database connection in MindsDB
Create OpenAI ML engine
Create classification and recommendation agents
Initialize knowledge bases (if Confluence credentials are provided)
Set up analytics jobs
Step 4: (Optional) Import Sample Banking Data
If you have sample banking conversation data, you can import it:
cd script python import_banking_data.py
This will:
Import conversations from CSV
Preprocess and aggregate conversations
Store them in PostgreSQL
The application works without sample data - you can process conversations via the API.
Step 5: Start the FastAPI Server
Start the application server:
python server.py
Or using uvicorn directly:
uvicorn app:app --host 0.0.0.0 --port 8000
Expected output:
====================================================================== Starting Banking Customer Service API Server... ====================================================================== Step 1: Initializing PostgreSQL database... ✓ PostgreSQL ready Step 2: Initializing MindsDB... ✓ MindsDB initialization completed Step 3: Connecting to MindsDB and registering agents... ✓ Connected to MindsDB ✓ Registered agent: classification_agent ✓ Registered agent: recommendation_agent Step 4: Initializing Jira client... ✓ Jira client configured (or ✗ if not configured) Step 5: Initializing Salesforce client... ✓ Salesforce client configured (or ✗ if not configured) ====================================================================== Server startup complete! ====================================================================== Starting Banking Customer Service API Server... API Documentation: http://localhost:8000/docs Health Check: http://localhost:8000/health
The server will be available at:
API Documentation (Swagger): http://localhost:8000/docs
Health Check: http://localhost:8000/health
Testing the Application
Test 1: Health Check
curl http://localhost:8000/health
Expected response:
{"status": "healthy", "database": "connected"}
Test 2: Process a Single Conversation
Use the provided test script:
python test_single_conversation.py
Or use curl:
curl -X POST "http://localhost:8000/api/process-conversations" \ -H "Content-Type: application/json" \ -d '{ "conversation_texts": [ "agent: Hello, how can I help you today?\nclient: I have an issue with my account balance..." ] }'
Test 3: Test with Recommendations
python test_recommendation.py
This tests the full workflow including AI-generated recommendations for unresolved cases.
Understanding the Workflow
When you send a conversation to the API:
Classification: The conversation is analyzed by the
classification_agentto:Generate a 2-3 sentence summary
Determine if the issue is RESOLVED or UNRESOLVED
Salesforce Integration: ALL conversations are logged to Salesforce (if configured)
Recommendation (for UNRESOLVED cases only):
The
recommendation_agentqueries the knowledge baseGenerates actionable recommendations based on policies
Creates a Jira ticket with the recommendations (if configured)
Quick Start Summary
# 1. Set environment variables echo "OPENAI_API_KEY=your_key" > .env # 2. Start Docker services docker-compose up -d # 3. Install dependencies pip install -r requirements.txt # 4. Initialize MindsDB (optional, auto-initializes on startup) python -m app.mindsdb.setup # 5. Start server python server.py # 6. Test curl http://localhost:8000/health python test_single_conversation.py python test_recommendation.py
Results
End-to-end automation: Complete workflow from call transcript ingestion to Jira ticket creation with zero manual intervention.
84% time reduction: Cases that previously required 15+ minutes of manual triage, summarization, and ticket creation now complete in under 2 minutes.
Production-ready architecture: MindsDB connects to enterprise data sources with standard authentication; our Python backend controls all write operations to Salesforce and Jira, maintaining security boundaries.
Rapid development: Full prototype built and deployed in 48 hours using MindsDB's declarative agent framework without custom RAG infrastructure or embedding pipelines.
What We Learned As Contributors
MindsDB's SQL-driven framework made debugging and prompt tuning significantly faster. Instead of parsing application logs, we could query agent execution history like any database table and analyze patterns across hundreds of runs to refine prompts quickly.
Model Selection Strategy
We matched models to operational needs. The summary and classification agent processes high volumes with tight latency requirements, so we use smaller, efficient models (gpt-5-nano, gpt-oss-120b). The recommendation agent handles fewer cases but requires deeper reasoning over complex policy documents, so we use more capable models (gpt-5-pro, gemini-2.5-pro) to reduce misaligned outputs that need human correction.
Explainability & Traceability
MindsDB's UI shows the complete execution trace: input, agent reasoning in the "Thoughts" panel, knowledge base queries, and retrieved data in the "Observation" panel. When outputs miss the mark, you can see exactly which knowledge base or table content influenced the decision. This transparency is essential for compliance audits and far superior to black-box implementations.
Conclusion
This demo was created to showcase MindsDB's capabilities in building production-ready AI applications with minimal infrastructure. It demonstrates how enterprises can automate complex workflows by combining AI agents, RAG knowledge bases, and existing data sources through a unified SQL interface.
Check out our project on GitHub, Auto-Banking Customer Service.
Watch the full demo on youtube:
Products
Open Source
© 2026 All rights reserved by MindsDB.

Start conversational analytics with MindsDB
Production-ready infrastructure for agentic analytics
Start conversational analytics with MindsDB
Production-ready infrastructure for agentic analytics

Products
Open Source
© 2026 All rights reserved by MindsDB.

Products
Open Source
© 2026 All rights reserved by MindsDB.
Start conversational analytics with MindsDB
Production-ready infrastructure for agentic analytics