Why Machine Learning at the Data Layer Works Best for Business Intelligence Systems
Why Machine Learning at the Data Layer Works Best for Business Intelligence Systems

Erik Bovee, Head of Business Development at MindsDB
Apr 5, 2021
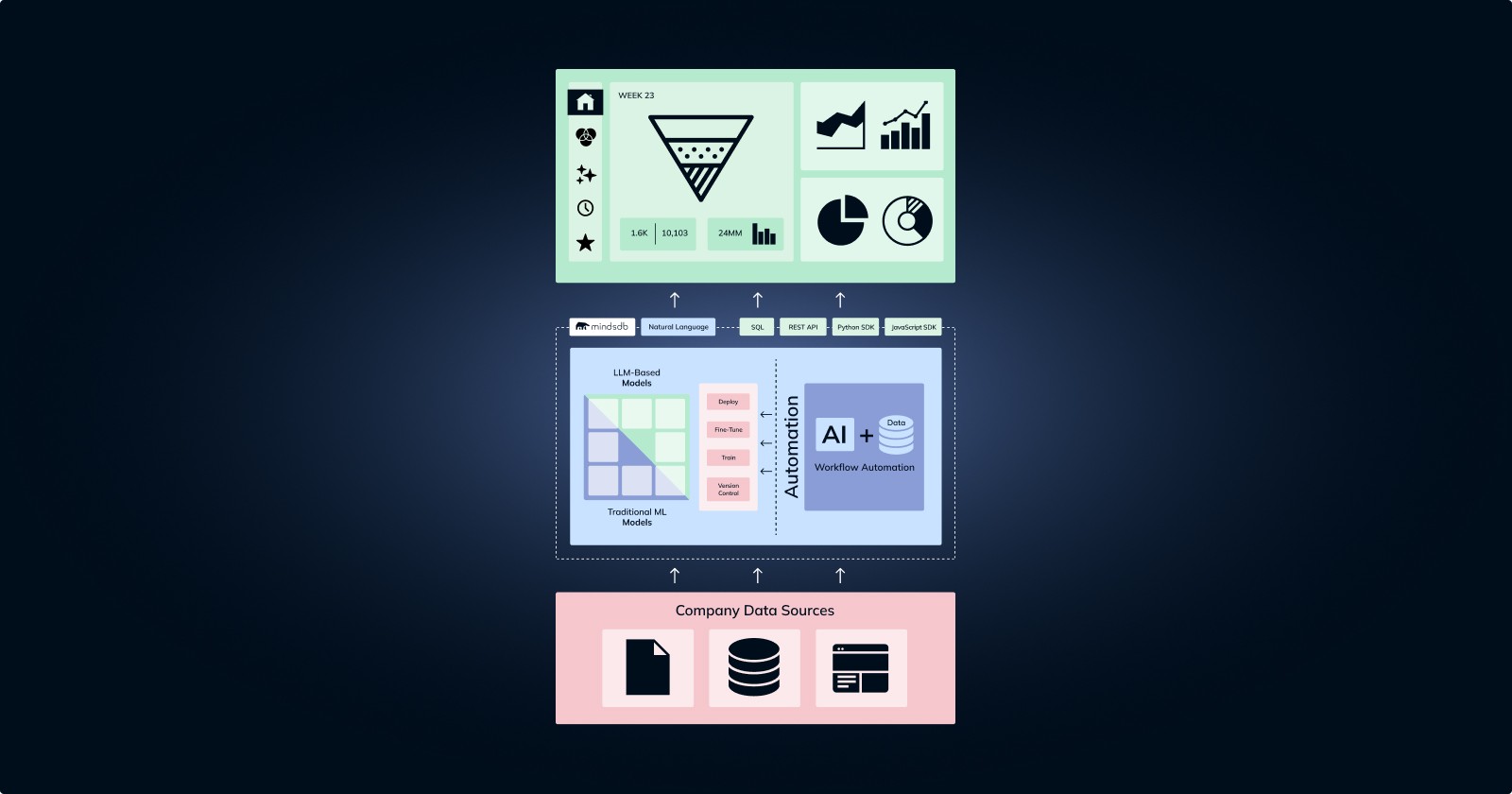
Incorporating machine learning into BI workflows has become common practice in the last few years, and BI tools benefit from recent developments to democratize machine learning by automating many of the complex tasks previously reserved for ML engineers. Just as libraries like Pytorch and TensorFlow made it easier (although still challenging) to build machine learning applications without having to code artificial neurons from scratch, automated machine learning (AutoML) takes over a lot of the time-consuming tasks around data prep, feature engineering, model selection, and training. We believe there are further fundamental improvements to the design of ML applications that can broaden its adoption and best support BI.
Machine learning works best at the data layer
Most applications access data from a database, and databases generally support a broad range of analytical or statistical functions to provide powerful analysis in an efficient manner for the overlying application. Why not also facilitate machine learning where the data actually lives, and offer a simple, common way to perform machine learning predictions with, for example, SQL commands? Here is a nice example of how Machine Learning works inside MariaDB:
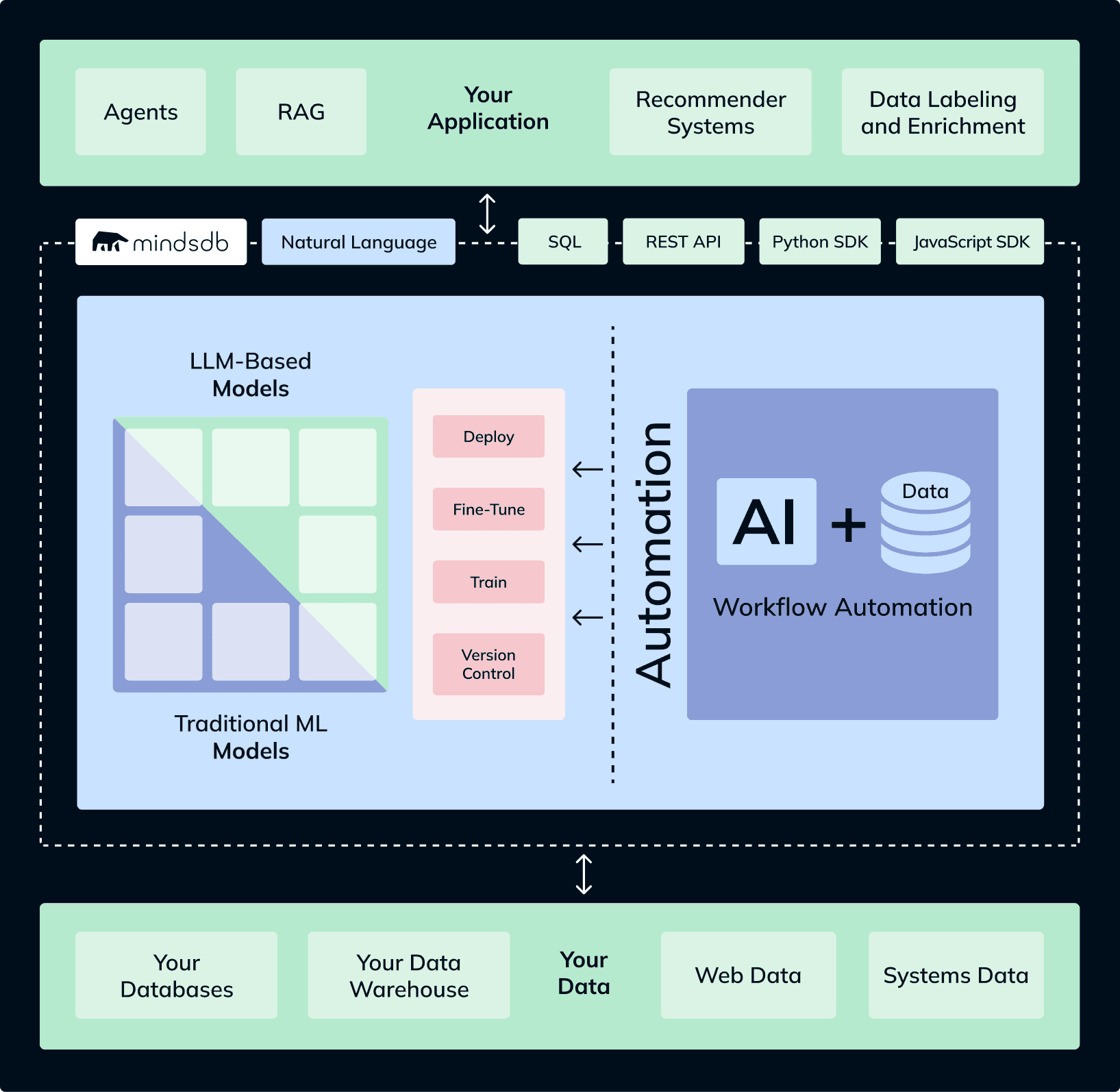
MindsDB simplifies this task with our local installation via Docker or MindsDB extension on Docker Desktop where you can connect your MariaDB database as an engine in our GUI.
Connecting MindsDB to your SQL database now means you can select data for training (the AutoML features do the rest) and then run predictions on target variables directly using something that looks and behaves like native tables. We call them ‘AI Tables’.
ML at the data layer saves time
There are some illustrative use cases with business intelligence systems that are a great example of why this approach is powerful. But let’s start with three things that are especially important for BI systems - efficient workflows, explainability (ML can be a bit of a black box, but BI systems are designed for highly visual and intuitive analysis), and finally expanding the traditional tool-set of the data scientist well beyond a few statistical libraries.
BI workflows with ML (and especially easy-to-use AutoML extensions) usually follow this pattern:

Extract data from a database or data warehouse.
Prep it (e.g. turn it into a flat file)
Load it into the BI tool
Export the data from the BI tool to the ML extension (and in the case of non-AutoML - model creation, etc.)
Train the ML
Run predictions on the data via the AutoML extension
Load those predictions back into the BI tool
Prepare visualization in the BI tool
We can immediately identify that there are unnecessary steps in the ETL process for preparing the model. What if AI Tables were exposed to the overlying BI tool via SQL commands? Thus, reducing the amount of steps taken to the following:

Select data from the GUI
Run AutoML from the GUI
Look deeply into the crystal ball
There is a huge amount of efficiency that comes from having AutoML at the data layer in this case, and that facilitates broader use of ML for experimentation and simply testing hypotheses around your business. Every ML prediction doesn’t have to be a mini-project. You can try things on the fly and not only increase the amount of insight, but the agility of your business planning.
“What am I looking at here?” Explainability of ML predictions
Too much simplicity raises the question - how do I know if the ML predictions are correct? This is a fundamental issue with machine learning in general: it can be a black box. The performance of complex artificial neural networks can be tough to explain even for researchers. But BI tools are pretty good at offering visualization that facilitates quick, intuitive analysis. AutoML platforms also generally offer features to identify outliers, bias in the data and confidence predictions, and these are even better when represented graphically: you can immediately see outliers, or you can color code data where predictions become less reliable.

However, these don’t really give insight into the mechanics or thresholds of a particular predicted result. One very powerful way to explain AI to business users is using counterfactual examples: the ‘what if’ scenarios. In a BI tool you can identify the values that contribute the most to a particular prediction and you can also change input values to see how they change the prediction. This is an example of running hypothetical scenarios that are best enabled with AI tables, rather than a looser coupling of BI and AutoML extensions. The user can ask questions directly from the predictive model and find out where the threshold of a prediction lies. By illustrating a diverse set of minimally changed inputs that change the prediction outcome, you can begin to visualize the pattern behind the prediction, and this is an essential step in gaining user trust.
Turn your BI tool into a real crystal ball
The above cases are examples of efficiencies and features facilitated by having ML live at the data layer, but there is something even more fundamental and powerful in the tight coupling of BI systems and AutoML: you turn your BI system into a crystal ball. The addition of ML expands the analyst’s tools so far beyond common statistical models that BI becomes a different product category. It’s essentially magic (albeit accurate and explainable magic). One of the most common types of data stored in business databases is time series. And time series are notoriously resistant to statistical analysis. Imagine you have a database filled with thousands upon thousands of product SKUs, each with 1000s of purchase records and time stamps. This represents a very large and challenging degree of cardinality, and if you wanted to predict, for example, which products are most likely to sell when, then you would have to lose granularity and use predictions based on large observable trends (e.g. Christmas season = more purchases) OR you would need to train a model for each SKU with time of purchase as input variables, which is computationally expensive and prohibitive. By exposing extremely large ML models, designed specifically for time series or natural language, as simple AI tables, a business can achieve a high degree of granularity AND accuracy in predicting around complex data sets.
Machine Learning has transformed BI
Over the years, ML has become an increasingly fundamental part of business intelligence, and to make that work well,we have found that machine learning models should be integrated deeper into the architectural stack, residing in the same layer as the data they augment and transform.. To see how this works in practice, and how it can help your business make a giant leap forward with machine learning, feel free to reach out to our team here.
About the author - Erik Bovee was a founding partner at Speedinvest, an early stage venture fund with $400M assets under management. He led the seed round in MindsDB and has recently joined the team as Vice President of Business Development.
Incorporating machine learning into BI workflows has become common practice in the last few years, and BI tools benefit from recent developments to democratize machine learning by automating many of the complex tasks previously reserved for ML engineers. Just as libraries like Pytorch and TensorFlow made it easier (although still challenging) to build machine learning applications without having to code artificial neurons from scratch, automated machine learning (AutoML) takes over a lot of the time-consuming tasks around data prep, feature engineering, model selection, and training. We believe there are further fundamental improvements to the design of ML applications that can broaden its adoption and best support BI.
Machine learning works best at the data layer
Most applications access data from a database, and databases generally support a broad range of analytical or statistical functions to provide powerful analysis in an efficient manner for the overlying application. Why not also facilitate machine learning where the data actually lives, and offer a simple, common way to perform machine learning predictions with, for example, SQL commands? Here is a nice example of how Machine Learning works inside MariaDB:
MindsDB simplifies this task with our local installation via Docker or MindsDB extension on Docker Desktop where you can connect your MariaDB database as an engine in our GUI.
Connecting MindsDB to your SQL database now means you can select data for training (the AutoML features do the rest) and then run predictions on target variables directly using something that looks and behaves like native tables. We call them ‘AI Tables’.
ML at the data layer saves time
There are some illustrative use cases with business intelligence systems that are a great example of why this approach is powerful. But let’s start with three things that are especially important for BI systems - efficient workflows, explainability (ML can be a bit of a black box, but BI systems are designed for highly visual and intuitive analysis), and finally expanding the traditional tool-set of the data scientist well beyond a few statistical libraries.
BI workflows with ML (and especially easy-to-use AutoML extensions) usually follow this pattern:
Extract data from a database or data warehouse.
Prep it (e.g. turn it into a flat file)
Load it into the BI tool
Export the data from the BI tool to the ML extension (and in the case of non-AutoML - model creation, etc.)
Train the ML
Run predictions on the data via the AutoML extension
Load those predictions back into the BI tool
Prepare visualization in the BI tool
We can immediately identify that there are unnecessary steps in the ETL process for preparing the model. What if AI Tables were exposed to the overlying BI tool via SQL commands? Thus, reducing the amount of steps taken to the following:
Select data from the GUI
Run AutoML from the GUI
Look deeply into the crystal ball
There is a huge amount of efficiency that comes from having AutoML at the data layer in this case, and that facilitates broader use of ML for experimentation and simply testing hypotheses around your business. Every ML prediction doesn’t have to be a mini-project. You can try things on the fly and not only increase the amount of insight, but the agility of your business planning.
“What am I looking at here?” Explainability of ML predictions
Too much simplicity raises the question - how do I know if the ML predictions are correct? This is a fundamental issue with machine learning in general: it can be a black box. The performance of complex artificial neural networks can be tough to explain even for researchers. But BI tools are pretty good at offering visualization that facilitates quick, intuitive analysis. AutoML platforms also generally offer features to identify outliers, bias in the data and confidence predictions, and these are even better when represented graphically: you can immediately see outliers, or you can color code data where predictions become less reliable.
However, these don’t really give insight into the mechanics or thresholds of a particular predicted result. One very powerful way to explain AI to business users is using counterfactual examples: the ‘what if’ scenarios. In a BI tool you can identify the values that contribute the most to a particular prediction and you can also change input values to see how they change the prediction. This is an example of running hypothetical scenarios that are best enabled with AI tables, rather than a looser coupling of BI and AutoML extensions. The user can ask questions directly from the predictive model and find out where the threshold of a prediction lies. By illustrating a diverse set of minimally changed inputs that change the prediction outcome, you can begin to visualize the pattern behind the prediction, and this is an essential step in gaining user trust.
Turn your BI tool into a real crystal ball
The above cases are examples of efficiencies and features facilitated by having ML live at the data layer, but there is something even more fundamental and powerful in the tight coupling of BI systems and AutoML: you turn your BI system into a crystal ball. The addition of ML expands the analyst’s tools so far beyond common statistical models that BI becomes a different product category. It’s essentially magic (albeit accurate and explainable magic). One of the most common types of data stored in business databases is time series. And time series are notoriously resistant to statistical analysis. Imagine you have a database filled with thousands upon thousands of product SKUs, each with 1000s of purchase records and time stamps. This represents a very large and challenging degree of cardinality, and if you wanted to predict, for example, which products are most likely to sell when, then you would have to lose granularity and use predictions based on large observable trends (e.g. Christmas season = more purchases) OR you would need to train a model for each SKU with time of purchase as input variables, which is computationally expensive and prohibitive. By exposing extremely large ML models, designed specifically for time series or natural language, as simple AI tables, a business can achieve a high degree of granularity AND accuracy in predicting around complex data sets.
Machine Learning has transformed BI
Over the years, ML has become an increasingly fundamental part of business intelligence, and to make that work well,we have found that machine learning models should be integrated deeper into the architectural stack, residing in the same layer as the data they augment and transform.. To see how this works in practice, and how it can help your business make a giant leap forward with machine learning, feel free to reach out to our team here.
About the author - Erik Bovee was a founding partner at Speedinvest, an early stage venture fund with $400M assets under management. He led the seed round in MindsDB and has recently joined the team as Vice President of Business Development.

Start Building with MindsDB Today
Power your AI strategy with the leading AI data solution.
© 2025 All rights reserved by MindsDB.
Start Building with MindsDB Today
Power your AI strategy with the leading AI data solution.
© 2025 All rights reserved by MindsDB.

Start Building with MindsDB Today
Power your AI strategy with the leading
AI data solution.
© 2025 All rights reserved by MindsDB.