Updated March 2024: a Comparative Analysis of Leading Large Language Models





In 2023, LLMs boomed, and new Large Language Models seemed to roll out each week.
Now in 2024, demand for advanced natural language processing capabilities continues to surge, and it's critical for technical leaders to keep up.
LLMs have revolutionized the way we interact with text, enabling us to communicate, analyze, and generate content with unprecedented sophistication. In this in-depth analysis, we delve into details on the leading LLMs, exploring their capabilities, applications, and performance. Our comparative analysis not only includes renowned OpenAI models but also sheds light on other noteworthy contenders such as LangChain, Anthropic, Cohere, and Google's Gemini.
Join us as we unravel the fascinating landscape of LLMs, uncover their unique features, and ultimately help you make informed decisions by harnessing the power of natural language processing systems.
Meet the Leading Large Language Models
We invite you to meet the leading large language models that are shaping the landscape of artificial intelligence. These remarkable models possess extraordinary capabilities in comprehending and generating text, setting new standards in natural language processing.
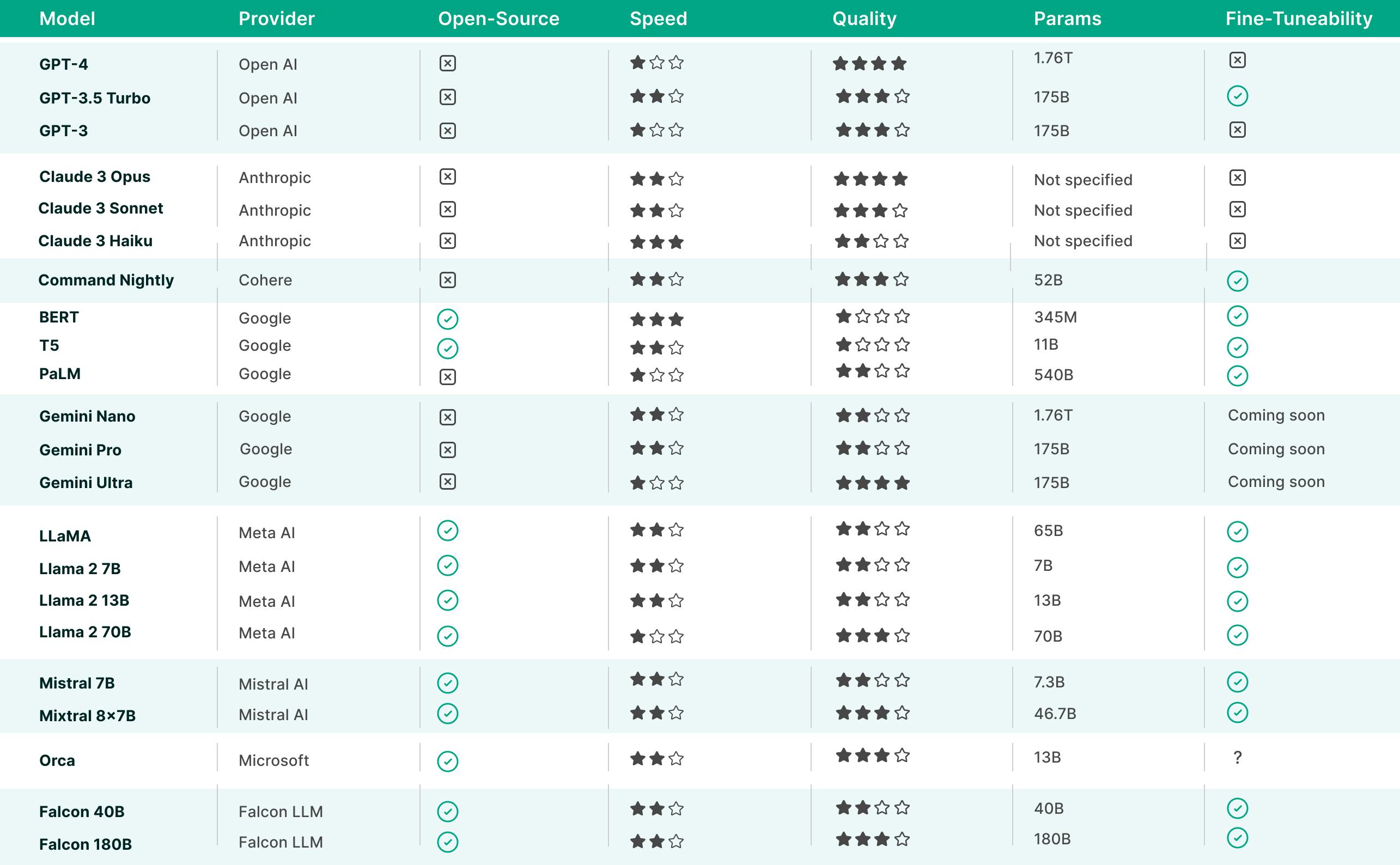
The values of Speed and Quality are approximated based on the following references:
https://thenewstack.io/cohere-vs-openai-in-the-enterprise-which-will-cios-choose/
https://www.theverge.com/2023/12/6/23990466/google-gemini-llm-ai-model
https://www.androidauthority.com/gemini-ultra-vs-gemini-pro-vs-gemini-nano-3392135/
https://www.promptfoo.dev/docs/guides/llama2-uncensored-benchmark-ollama/
https://promptengineering.org/how-does-llama-2-compare-to-gpt-and-other-ai-language-models/
https://www.datacamp.com/tutorial/introduction-to-falcon-40b
Now, let's examine each of these models in more detail.
OpenAI
OpenAI, an artificial intelligence research laboratory, has carved a remarkable path in advancing the boundaries of human-like language processing.

OpenAI released numerous influential language models, including the entire GPT family such as GPT-3 and GPT-4, which power their ChatGPT product, that have captured the imagination of developers, researchers, and enthusiasts worldwide.
We encourage you to explore examples and tutorials that present the usage of OpenAI models within MindsDB.
OpenAI models have garnered attention for their impressive features and state-of-the-art performance. These models possess remarkable capabilities in natural language understanding and generation. They excel at a wide range of language-related tasks, including text completion, translation, question-answering, and more.
The GPT family of models, including GPT-4 and GPT-3.5 Turbo, has been trained on internet data, codes, instructions, and human feedback, with over a hundred billion parameters, which ensures the quality of the models.
OpenAI provides different usage options through their API, including fine-tuning, where users can adapt the models to specific tasks or domains by providing custom training data. Additionally, options like temperature and max_tokens control the output style and length of the generated text, allowing users to customize the behavior of the models according to their specific needs.
OpenAI has pioneered the development of Reinforcement Learning from Human Feedback (RLHF), a technique that shapes the behavior of their models in chat contexts. RLHF involves training AI models by combining human-generated feedback with reinforcement learning methods. Through this approach, OpenAI's models learn from interactions with humans to improve their responses.
In terms of performance, OpenAI models often achieve top-tier results in various language benchmarks and evaluations. However, it's important to note that the performance and capabilities of OpenAI models can vary depending on the specific task, input data, and the fine-tuning process.
Anthropic
Anthropic is an organization that seeks to tackle some of the most profound challenges in artificial intelligence and shape the development of advanced AI systems. With a focus on robustness, safety, and value alignment, Anthropic aims to address critical ethical and societal considerations surrounding AI.

In early March, Anthropic introduced the next generation of Claude. Claude 3 models can facilitate open-ended conversation, collaboration on ideas, coding tasks, working with text, and processing and analyzing visual input such as charts, graphs, and photos.
The Claude 3 model family offers three models listed here in ascending order of capability and cost: Haiku, Sonnet, and Opus.
Claude 3 Haiku is the fastest and most compact model as compared to the other Claude 3 models.
Claude 3 Sonnet provides a balance between capability and speed. It is 2x faster than Claude 2 and Claude 2.1 with higher quality output.
Claude 3 Opus is the most capable out of all Claude 3 models and outperforms other LLMs on most of the common evaluation benchmarks for AI systems.
The key features of Claude 3 models include multilingual capabilities, vision and image processing, and steerability and ease of use.
Anthropic's Claude 3 models utilize a feature known as constitutional AI, which involves a two-phase process: supervised learning and reinforcement learning. It addresses the potential risks and harms associated with artificial intelligence systems utilizing AI feedback. By incorporating the principles of constitutional learning, it aims to control AI behavior more precisely.
Cohere
Cohere, an artificial intelligence research company, bridges the gap between humans and machines, focusing on creating AI technologies that augment human intelligence.

Cohere has successfully developed the Command-nightly model that excels at interpreting instruction-like prompts and exhibits better performance and fast response, making it a great option for chatbots.
Cohere’s Command-nightly model facilitates content generation, summarization, and search, operating at a massive scale to meet enterprise needs. With a focus on security and performance, Cohere develops high-performance language models that can be deployed on public, private, or hybrid clouds, ensuring data security.
The Command-nightly has been trained on internet data and instructions, which decreases its quality as compared to GPT models but increases the speed of inference. This model has been trained using 52 billion parameters, and it is the most up-to-date version of the Command models.
It is accessible through a user-friendly API and platform, facilitating a range of applications. These include semantic search, text summarization, generation, and classification.
This model is pre-trained on vast amounts of textual data, making it easy to use and customize. Furthermore, Cohere's multilingual semantic search capability supports over 100 languages, enabling organizations to overcome language barriers and reach a wider audience.
To facilitate experimentation and exploration, Cohere offers the Cohere Playground - a visual interface that allows users to test the capabilities of its model without the need to write any code.
Google, a global technology giant, has developed several pioneering large language models (LLMs) that have reshaped the landscape of natural language processing.

Google has introduced language models such as BERT (Bidirectional Encoder Representations from Transformers), T5 (Text-to-Text Transfer Transformer), and PaLM (Pathways Language Model). Recently, Google announced the Gemini model family, out of which the Gemini Ultra model outperforms the OpenAI’s GPT-4 model in most benchmarks, providing support for not only textual data but also image, audio, and video data, natively.
We encourage you to explore the Hugging Face hub for the available models developed by Google. You can use them within MindsDB, as shown in this example.
Google is a pioneer in the large language model research line, starting with the publication of the original Transformer architecture which has been the base for all other models we’ve mentioned in this article. In fact, models like BERT (Bidirectional Encoder Representations from Transformers) were considered LLMs at the time, only to be succeeded by much larger models like T5 (Text-to-Text Transfer Transformer), and PaLM (Parameterized Language Model).
BERT leverages transformer-based architectures to provide a deep contextual understanding of the text. It is pre-trained on massive amounts of unlabeled data and can be fine-tuned for specific tasks. BERT captures the contextual relationships between words in a sentence by considering both the left and right context. This bidirectional approach allows it to comprehend the nuances of language more effectively.
T5 is a versatile and unified framework for training large language models. Unlike previous models that focus on specific tasks, T5 adopts a text-to-text transfer learning approach. T5 can be trained on a variety of natural language processing tasks, including translation, summarization, text classification, and more. It follows a task-agnostic approach; it is designed to handle a wide range of tasks without being explicitly trained for each individual task. T5 utilizes a transformer-based architecture that facilitates efficient training and transfer of knowledge across different tasks. It demonstrates the ability to generate high-quality responses and perform well across various language-related tasks.
PaLM focuses on capturing syntactic and semantic structures within sentences. It utilizes linguistic structures such as parse trees to capture the syntactic relationships between words in a sentence. It also integrates semantic role labeling to identify the roles played by different words in a sentence. By incorporating syntactic and semantic information, PaLM aims to provide more meaningful sentence representations that can benefit downstream tasks such as text classification, information retrieval, and sentiment analysis. Additionally, it supports scaling up to 540 billion parameters to achieve breakthrough performance.
Google's Gemini models represent the company’s latest advancement in artificial intelligence, providing flexibility and scalability. The Gemini 1.0 version comes in various sizes, including Ultra for highly complex tasks, Pro for scaling across a wide range of tasks, and Nano for efficient on-device operations.
What sets Gemini apart is its native multimodal design, enabling seamless understanding and reasoning across diverse inputs like text, images, and audio. Gemini's sophisticated reasoning capabilities make it proficient at extracting insights from vast amounts of data in fields from science to finance. Gemini excels in explaining complex reasoning, especially in subjects like math and physics. Gemini also emerges as a leading foundation model for coding, with its Ultra version excelling in coding benchmarks.
Meta AI
Meta AI, an artificial intelligence laboratory, has released large language models including LLaMA (Large Language Model Meta AI) and Llama 2.

LLaMA models are not the biggest models by parameter count, but they are still huge and trained on vast amounts of data following best training practices, leading to high-performing models that enable researchers without extensive resources to explore and study these models, thus democratizing access to this rapidly evolving field. These foundation models can be deployed with comparatively less computing power and resources thanks to many optimizations introduced by the open-source community, making them ideal for fine-tuning and experimentation across various tasks.
The original LLaMA model family is a collection of large language models, encompassing a wide parameter range from 7B to 65B. Through meticulous training on trillions of tokens sourced exclusively from publicly available datasets, the developers of LLaMA demonstrate the possibility of achieving cutting-edge performance without the need for proprietary or inaccessible data sources. Notably, LLaMA-13B showcases superior performance compared to the renowned GPT-3 (175B) across multiple benchmarks, while LLaMA-65B competes impressively with top-tier models like PaLM-540B.
On the other hand, Llama 2 offers three model sizes: 7B, 13B, and 70B. In addition to base pre-trained variants, it also offers versions aligned through Reinforcement Learning from Human Feedback (RLHF) and reward modeling. Thanks to this, Llama 2 excels in generating text, summarizing content, and engaging in human-like conversations. It leverages a context length twice that of its predecessor (Llama 1) and is trained on 2 trillion tokens with over 1 million human annotations. Llama 2 outperforms other open-source language models across various benchmarks, showcasing proficiency in reasoning, coding, and knowledge tests. Llama 2's applications extend to creating content, writing emails, generating summaries, expanding sentences, and providing answers. Llama 2's emphasis on safety sets it apart, with benchmark results indicating lower violation output compared to its competitors.
Mistral AI
Mistral AI, a Paris-based AI company, has recently gained prominence in the AI sector. Positioned as a French counterpart to OpenAI, Mistral distinguishes itself by emphasizing smaller models with impressive performance metrics. Some of Mistral's models can operate locally, featuring open weights that can be freely downloaded and utilized with fewer restrictions compared to closed AI models from competitors like OpenAI.

Mistral 7B is a 7.3 billion-parameter model that showcases strong performance across various benchmarks. Notably, it outperforms Llama 2 13B on all benchmarks and surpasses Llama 1 34B on many. While excelling in English tasks, Mistral 7B approaches CodeLlama 7B performance on coding-related tasks. This model is optimized for faster inference through Grouped-query attention (GQA) and efficiently handles longer sequences at a smaller cost with Sliding Window Attention (SWA). Released under the Apache 2.0 license, Mistral 7B can be freely used without restrictions. Users can download and use it locally, deploy it on cloud platforms like AWS, GCP, or Azure, and access it on HuggingFace. Additionally, Mistral 7B is easily fine-tuned for various tasks, demonstrated by a chat model that outperforms Llama 2 13B in chat-related applications.
Mixtral 8x7B is a Sparse Mixture of Experts model (SMoE) with open weights, licensed under Apache 2.0. With remarkable capabilities, Mixtral outperforms Llama 2 70B on most benchmarks, offering 6x faster inference and establishing itself as the strongest open-weight model with an advantageous cost/performance profile. Particularly noteworthy is its competitive performance against GPT3.5 on standard benchmarks. Mixtral has been pre-trained on data from the open web. It excels in handling a context of 32k tokens and supports multiple languages, including English, French, Italian, German, and Spanish. It demonstrates robust performance in code generation and can be fine-tuned into an instruction-following model. Mixtral operates as a sparse mixture-of-experts network, employing a decoder-only model with a unique feedforward block that selects from 8 distinct groups of parameters. With 46.7B total parameters but only using 12.9B parameters per token, Mixtral achieves input processing and output generation at the speed and cost of a 12.9B model.
Microsoft
Microsoft leverages its cloud computing platform, Azure, to provide a comprehensive suite of AI services, including machine learning tools. The company actively engages in AI research, contributing to advancements in natural language processing.

Orca is a model that prioritizes three key areas: synthetic data creation, enhanced reasoning capabilities, and model specialization. Orca is designed to generate tailored and high-quality synthetic data specifically for the training of small models. It aims to empower smaller language models with improved reasoning abilities, typically associated with much larger models. Orca emphasizes the creation of specialized models, each equipped with unique capabilities or custom behaviors. Orca is a 13B parameter model that compares to OpenAI's GPT-3.5 Turbo model in terms of performance.
Falcon LLM
Falcon LLM introduces a suite of AI models, including the Falcon 180B, 40B, 7.5B, and 1.3B parameter models.

Falcon 40B, an open-source AI model with 40 billion parameters, achieved top-ranking status on Hugging Face's leaderboard for large language models (LLMs) upon its launch. Trained on one trillion tokens, Falcon 40B operates across multiple languages and is offered royalty-free with weights, contributing to the democratization of AI technology. Its use of training compute is more efficient compared to other models, utilizing only 75% of GPT-3's, 40% of Chinchilla AI's, and 80% of PaLM-62B's. The model's development emphasizes the quality of training data, with nearly five trillion tokens gathered from diverse sources through a meticulous custom data pipeline, ensuring high-quality pre-training data.
Falcon 180B, a language model with 180 billion parameters and trained on 3.5 trillion tokens, currently leads the Hugging Face Leaderboard for pre-trained Open Large Language Models. Available for both research and commercial applications, this model excels in tasks such as reasoning, coding, proficiency, and knowledge tests, surpassing competitors like Meta's Llama 2. Falcon 180B closely follows OpenAI's GPT-4 and performs comparably with Google's PaLM 2 Large, despite being only half the size of the latter model.
Select your champion
Navigating the landscape of large language models has revealed a multitude of impressive contenders, each with its own set of features and performance strengths. LLMs offer remarkable advancements in natural language processing. However, the choice of the ultimate winner depends on the specific requirements and applications.
Organizations must carefully consider factors such as fine-tuning capabilities, multilingual support, automation features, licensing, and security aspects to determine which LLM aligns best with their needs.
As the LLM landscape continues to evolve, ongoing research and advancements promise even more innovative and powerful models. The future holds exciting possibilities as these models push the boundaries of language understanding, enabling us to unlock new opportunities in various industries and domains.
Check us out on GitHub.