Machine Learning for a Shopify store - a step by step guide
Machine Learning for a Shopify store - a step by step guide

Zoran Pandovski, Engineering Manager(Backend)
Jun 10, 2022
With the volume of data increasing exponentially, it’s critical for businesses focused on e-commerce to leverage that data as quickly and efficiently as possible. Machine learning represents a disruption to increase predictive capabilities and augment human decision-making for use cases like price, assortment and supply chain optimization, inventory management, delivery management, and customer support. In this ‘how-to’ guide, we’ll provide step-by-step instructions showing you how to simply make predictions using Shopify order data and MindsDB, an open-source in-database ML framework. It doesn’t require significant data-science skills (“low code”) and at the same time has unique advantages for time-series predictions.
This guide consists of four parts:
Accessing MindsDB
Connecting Shopify to MindsDB as a datasource
Create a Predictor for forecasting purchase orders (a machine learning model that learns from Shopify data).
Make Predictions with simple data queries
Step 1: Accessing MindsDB GUI
You can access MindsDB via local Docker installation, MindsDB’s extension via Docker Desktop or AWS Marketplace. You will be able to interact with MindsDB’s GUI where you can perform tasks with its SQL Editor.
Step 2: Connecting your Shopify data to MindsDB
Once you have successfully installed MindsDB and accessed its GUI, you can connect Shopify to MindsDB as a data source by using SQL Syntax.
To connect via SQL syntax, make sure you have installed the dependency for Shopify.
For dependencies, navigate to Settings (the tool icon) and select Manage Integrations. Search for Shopify and select the ‘Install’ button.
The CREATE DATABASE syntax will be used to establish a connection.
The required arguments to establish a connection are as follows:
shop_url: a required URL to your Shopify store.
access_token: a required access token to use for authentication.
CREATE DATABASE shopify_datasource WITH ENGINE = 'shopify', PARAMETERS = { "shop_url": "your-shop-name.myshopify.com", "access_token": "shppa_..." }
Once Shopify is connected, you can query your data.
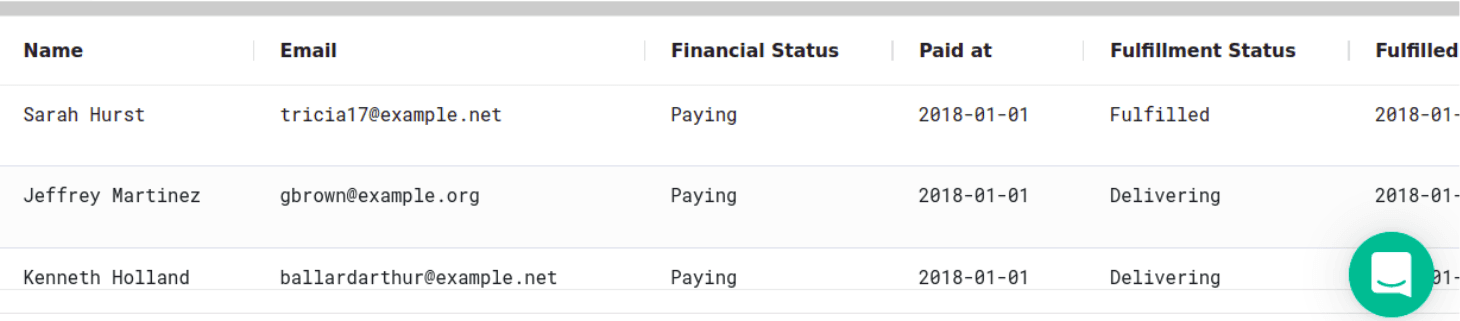
SELECT * FROM shopify_datasource.shopify_orders LIMIT 10
And you will get the result in the console of the SQL Editor:
Now that the data has been successfully uploaded, we can move on to create and train an AI model.
STEP 3 Creating an AI model
Now, let's specify that we want to forecast the Total column, which is a moving average of the historical price for sales. However, looking at the data you can see several entries for the same date, depending on several factors: the vendor, the line item, and the shipping country. We want to generate forecasts to predict the behavior of Total (price) by vendor, line-item, and country for the 7 days. MindsDB makes it simple so that we don't need to repeat the predictor creation process for every group there is. Instead, we can just group for both columns and the predictor will learn from all series and enable all forecasts!
In the SQL Editor, we will make use of the CREATE MODEL statement to create and train a model.
CREATE MODEL mindsdb.shopify_model FROM shopify_datasource (SELECT Total, Vendor, `Created at`, `Lineitem name`, `Shipping country` FROM shopify_orders) PREDICT Total ORDER BY `Created at` GROUP BY `Lineitem name`, `Shipping country`, Vendor WINDOW 30 HORIZON 7
You can check up on the model’s status by running the DESCRIBE syntax.
DESCRIBEOnce the status shows complete, you can go ahead and query the model
Step 3: Make Predictions
Once the model's status is complete, you can query it as a table to get forecasts for a given period of time. Usually, you'll want to know what happens right after the latest training data point that was fed, for which we have a special bit of syntax, the "LATEST" keyword:
SELECT m.'Created at' as date, m.Total as forecast FROM mindsdb.shopify_test_model as m JOIN shopify_datasource.shopify_orders as t WHERE t.'Created at' > LATEST AND t.'LineItem name' = 'basketball top' AND t.'Shipping Country'='Spain' AND t.'Vendor'='store1' LIMIT 7
You will get the following results:
+--------------+-------------------------------+ | date | forecast | +--------------+-------------------------------+ | 2024-01-02 | 32.204026432145245 | +--------------+-------------------------------+ | 2024-01-03 | 29.460360721092096 | +--------------+-------------------------------+ | 2024-01-04 | 32.066075132654854 | +--------------+-------------------------------+ | 2024-01-05 | 26.096503045126078 | +--------------+-------------------------------+ | 2024-01-06 | 25.103608040660851 | +--------------+-------------------------------+ | 2024-01-07 | 29.022503408569214 | +--------------+-------------------------------+ | 2024-01-08 | 34.798601402736582
Now, try changing LineItem Name to 'winter coat', Vendor to 'store2' or Shipping Country to the 'Netherlands', and see how the forecast varies. This is because MindsDB recognizes each grouping as being its own different time series.
Note: for the convenience of analysis it is better to use MindsDB with your database or analytical solution. It speaks the SQL Wire Protocol and thus works with the majority of business intelligence tools.
CONCLUSION
We have successfully created a machine learning predictive model using a Shopify order data file and made predictions. MindsDB is an amazingly helpful tool that puts the power in your hands to create and analyze predictions in order to make better business decisions for your Shopify store!
NEXT STEPS:
Star the MindsDB repository and connect to the Slack Community.
With the volume of data increasing exponentially, it’s critical for businesses focused on e-commerce to leverage that data as quickly and efficiently as possible. Machine learning represents a disruption to increase predictive capabilities and augment human decision-making for use cases like price, assortment and supply chain optimization, inventory management, delivery management, and customer support. In this ‘how-to’ guide, we’ll provide step-by-step instructions showing you how to simply make predictions using Shopify order data and MindsDB, an open-source in-database ML framework. It doesn’t require significant data-science skills (“low code”) and at the same time has unique advantages for time-series predictions.
This guide consists of four parts:
Accessing MindsDB
Connecting Shopify to MindsDB as a datasource
Create a Predictor for forecasting purchase orders (a machine learning model that learns from Shopify data).
Make Predictions with simple data queries
Step 1: Accessing MindsDB GUI
You can access MindsDB via local Docker installation, MindsDB’s extension via Docker Desktop or AWS Marketplace. You will be able to interact with MindsDB’s GUI where you can perform tasks with its SQL Editor.
Step 2: Connecting your Shopify data to MindsDB
Once you have successfully installed MindsDB and accessed its GUI, you can connect Shopify to MindsDB as a data source by using SQL Syntax.
To connect via SQL syntax, make sure you have installed the dependency for Shopify.
For dependencies, navigate to Settings (the tool icon) and select Manage Integrations. Search for Shopify and select the ‘Install’ button.
The CREATE DATABASE syntax will be used to establish a connection.
The required arguments to establish a connection are as follows:
shop_url: a required URL to your Shopify store.
access_token: a required access token to use for authentication.
CREATE DATABASE shopify_datasource WITH ENGINE = 'shopify', PARAMETERS = { "shop_url": "your-shop-name.myshopify.com", "access_token": "shppa_..." }
Once Shopify is connected, you can query your data.
SELECT * FROM shopify_datasource.shopify_orders LIMIT 10
And you will get the result in the console of the SQL Editor:
Now that the data has been successfully uploaded, we can move on to create and train an AI model.
STEP 3 Creating an AI model
Now, let's specify that we want to forecast the Total column, which is a moving average of the historical price for sales. However, looking at the data you can see several entries for the same date, depending on several factors: the vendor, the line item, and the shipping country. We want to generate forecasts to predict the behavior of Total (price) by vendor, line-item, and country for the 7 days. MindsDB makes it simple so that we don't need to repeat the predictor creation process for every group there is. Instead, we can just group for both columns and the predictor will learn from all series and enable all forecasts!
In the SQL Editor, we will make use of the CREATE MODEL statement to create and train a model.
CREATE MODEL mindsdb.shopify_model FROM shopify_datasource (SELECT Total, Vendor, `Created at`, `Lineitem name`, `Shipping country` FROM shopify_orders) PREDICT Total ORDER BY `Created at` GROUP BY `Lineitem name`, `Shipping country`, Vendor WINDOW 30 HORIZON 7
You can check up on the model’s status by running the DESCRIBE syntax.
DESCRIBEOnce the status shows complete, you can go ahead and query the model
Step 3: Make Predictions
Once the model's status is complete, you can query it as a table to get forecasts for a given period of time. Usually, you'll want to know what happens right after the latest training data point that was fed, for which we have a special bit of syntax, the "LATEST" keyword:
SELECT m.'Created at' as date, m.Total as forecast FROM mindsdb.shopify_test_model as m JOIN shopify_datasource.shopify_orders as t WHERE t.'Created at' > LATEST AND t.'LineItem name' = 'basketball top' AND t.'Shipping Country'='Spain' AND t.'Vendor'='store1' LIMIT 7
You will get the following results:
+--------------+-------------------------------+ | date | forecast | +--------------+-------------------------------+ | 2024-01-02 | 32.204026432145245 | +--------------+-------------------------------+ | 2024-01-03 | 29.460360721092096 | +--------------+-------------------------------+ | 2024-01-04 | 32.066075132654854 | +--------------+-------------------------------+ | 2024-01-05 | 26.096503045126078 | +--------------+-------------------------------+ | 2024-01-06 | 25.103608040660851 | +--------------+-------------------------------+ | 2024-01-07 | 29.022503408569214 | +--------------+-------------------------------+ | 2024-01-08 | 34.798601402736582
Now, try changing LineItem Name to 'winter coat', Vendor to 'store2' or Shipping Country to the 'Netherlands', and see how the forecast varies. This is because MindsDB recognizes each grouping as being its own different time series.
Note: for the convenience of analysis it is better to use MindsDB with your database or analytical solution. It speaks the SQL Wire Protocol and thus works with the majority of business intelligence tools.
CONCLUSION
We have successfully created a machine learning predictive model using a Shopify order data file and made predictions. MindsDB is an amazingly helpful tool that puts the power in your hands to create and analyze predictions in order to make better business decisions for your Shopify store!
NEXT STEPS:
Star the MindsDB repository and connect to the Slack Community.

Start Building with MindsDB Today
Power your AI strategy with the leading AI data solution.
© 2025 All rights reserved by MindsDB.
Start Building with MindsDB Today
Power your AI strategy with the leading AI data solution.
© 2025 All rights reserved by MindsDB.

Start Building with MindsDB Today
Power your AI strategy with the leading
AI data solution.
© 2025 All rights reserved by MindsDB.